Mi suscripción de $10 me da un límite de $60 en consumo de API, de los cuales ya usé $50 en apenas 11 días. Eso me hizo preguntarme: ¿qué pasaría si me paso a Claude Code? Durante este tiempo también estuve probando el plan pro de Claude Code, pero me encontré con límites de uso que me hicieron cuestionar si realmente es la mejor opción para mi patrón de uso, principalmente cuando usaba Claude Opus 4.7.
Acá van los datos reales. Cuánto gasté, en qué modelos, qué pasaría con los límites de Claude Code y por qué pagar más no siempre significa un mejor setup.
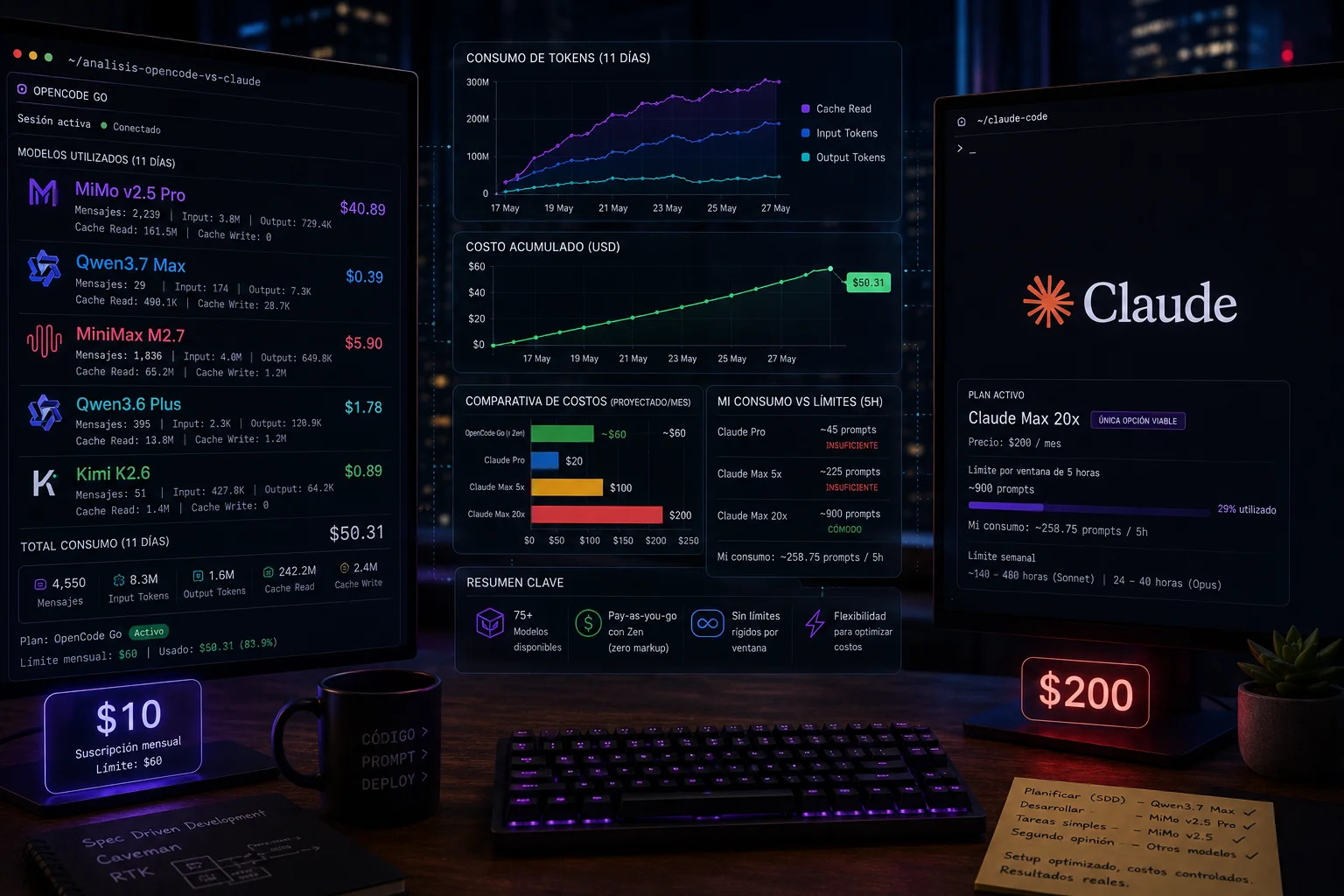
Mi uso de Opencode Go en 11 días
Resumen general
| Métrica | Valor |
|---|---|
| Costo total | $50.31 |
| Costo promedio/día | $4.19 |
| Tokens promedio/sesión | 533.7K |
| Tokens media/sesión | 44.7K |
| Input | 8.3M |
| Output | 1.6M |
| Cache Read | 242.2M |
| Cache Write | 2.4M |
Esto no quiere decir que pagué $50.31. Pagué $10 por la suscripción, pero generé un consumo de $50.31. El consumo es lo que determina si me paso del límite mensual ($60) o no.
Uso por modelo
| Modelo | Mensajes | Input Tokens | Output Tokens | Cache Read | Cache Write | Costo |
|---|---|---|---|---|---|---|
| MiMo-v2.5-pro | 2,239 | 3.8M | 729.4K | 161.5M | 0 | $40.89 |
| MiniMax M2.7 | 1,836 | 4.0M | 649.8K | 65.2M | 1.2M | $5.90 |
| qwen3.6-plus | 395 | 2.3K | 120.9K | 13.8M | 1.2M | $1.78 |
| kimi-k2.6 | 51 | 427.8K | 64.2K | 1.4M | 0 | $0.89 |
| qwen3.7-max | 29 | 174 | 7.3K | 490.1K | 28.7K | $0.39 |
Análisis de los números
MiMo-v2.5-pro se llevó el 81% del presupuesto ($40.89 de $50.31). Tiene sentido, fue el modelo con el que construí algunos proyectos y donde más tiempo estuve experimentando. Además, esto fue antes de que Xiaomi MiMo bajara los precios de sus APIs, lo que lo hace aún más atractivo para desarrolladores con consumo alto. Si fuera con los precios actuales, el costo de Mimo v2.5 Pro sería de $2.86, un 93% menos que los $40.89 que pagué, representaría solo el 5.7% del consumo total.
MiniMax M2.7 procesó el 41% de mis mensajes (1,836 de 4,550) y solo costó el 12% del total ($5.90). Mi patrón es claro: delego tareas repetitivas a modelos baratos y reservo el premium para razonamiento profundo. MiniMax M2.7 cuesta $0.3 por millón de tokens de entrada y $1.2 por millón de tokens de salida, muy por debajo de la mayoría de los otros modelos.
El costo por mensaje:
Costo total: $50.31
Total mensajes: 4,550
Costo por mensaje: $0.011
El sistema leyó 242.2M de tokens del caché. Está reutilizando contexto de forma agresiva para mantener memoria entre sesiones. Sin ese caché, el costo de input se iría a las nubes.
Durante los 11 días, estuve trabajando casi que 100% del tiempo con Vibe Coding, lo que explica el alto número de mensajes y tokens. Puedo decir que los modelos utilizados me sorprendieron mucho, especialmente Mimo v2.5 Pro y MiniMax M2.7, que lograron desarrollo real, entendiendo contexto complejo y generando código de alta calidad. Lo único que tuve que hacer es definir bien el plan con Spec Driven Development (SDD) y iterar en esta etapa.
Los límites del plan de Claude Code
Los números concretos de mi consumo promedio:
- 4,550 mensajes en 11 días = 414 mensajes/día
- Asumiendo 8 horas de uso activo: 51.75 mensajes/hora
- En una ventana de 5 horas: 258.75 mensajes
Ahora comparemos con cada plan de Claude Code:
Pro
- Precio: $20/mes
- Límite por ventana de 5 horas: ~45 prompts
- Límite semanal: ~40–80 horas de Sonnet
Con mi promedio de 258.75 mensajes por ventana de 5 horas, el plan Pro no funcionaría. A media mañana ya estaría viendo errores de rate limit. No es una opción viable para uso intensivo.
Max 5x
- Precio: $100/mes
- Límite por ventana de 5 horas: ~225 prompts
- Límite semanal: ~140–240 horas de Sonnet + 15-35 horas de Opus
Con 258.75 mensajes por ventana, ya supero el límite de 225 mensajes, imagínate con Opus que consume más rápido el límite (~35% más tokens que Sonnet).
Max 20x
- Precio: $200/mes
- Límite por ventana de 5 horas: ~900 prompts
- Límite semanal: ~140–480 horas de Sonnet + 24-40 horas de Opus
Con 258.75 mensajes por ventana, consumiría el ~29% del límite base (900 mensajes). Pero cuesta $200/mes.
Claude Code te encierra en modelos de Anthropic. Pierdes el acceso a MiniMax, Qwen, Kimi, Mimo y el resto del stack que hoy hace el trabajo pesado por centavos.
Tabla comparativa: lado a lado
| Aspecto | OpenCode Go (+ Zen) | Claude Pro | Claude Max 5x | Claude Max 20x |
|---|---|---|---|---|
| Costo base/mes | $10 | $20 | $100 | $200 |
| Mi gasto proyectado/mes | ~$60 | $20 | $100 | $200 |
| Modelos disponibles | 75+ | Solo Claude | Solo Claude | Solo Claude |
| Límite por 5h | Flexible | ~45 prompts | ~225 prompts | ~900 prompts |
| Mi consumo vs límite | Sin techo | Insuficiente | Insuficiente | Cómodo |
| Flexibilidad de modelos | Alta | Baja | Baja | Baja |
| Acceso a Opus | Sí (vía API) | No | Sí (xhigh) | Sí (xhigh) |
Claude Max 20x es la única opción que me da margen para mi patrón de uso actual. Pero cuesta $200/mes, un salto enorme comparado con los $10 de OpenCode Go. Y ese costo no se justifica si puedo manejar mi consumo con OpenCode Go + Zen por mucho menos, con la flexibilidad de modelos que necesito. Si me paso del límite de $60, simplemente recargo créditos en Zen y sigo trabajando sin interrupciones.
Opencode Go también tiene límites de uso, pero son mucho más flexibles que los de Claude Code. Puedo usar diferentes modelos según la tarea, mejorar mis prompts para reducir tokens y ajustar mi consumo sin preocuparme por límites rígidos.
OpenCode Zen
Para los que no les alcanza con la suscripción base de OpenCode Go, hay un camino: OpenCode Zen, que se activa automáticamente cuando superas el límite de $60.
Es pay-as-you-go. Agregas créditos de $10, pagas solo lo que usas, y si quieres, cuando tu balance baja de $5 se recarga automáticamente. Sin compromiso mensual, sin límites de “prompts por 5 horas”.
Si mantengo este mismo ritmo en OpenCode Go, para cubrir mi faltante este mes, necesitaría agregar unos $50-60 en créditos Zen. Eso me da exactamente lo que necesito sin cambiar de herramienta ni perder los modelos que uso.
OpenCode Zen ofrece zero markup. Pagas los modelos al precio de la API original, sin recargos. Tienes tu propia cuenta de API sin pelearte con múltiples providers.
No es permanente. Puedo cancelar cuando quiera y volver a mi suscripción de $10. Es un puente, no una mudanza.
Xiaomi MiMo Token Plan
El Token Plan es el sistema de suscripción por créditos de Xiaomi MiMo, diseñado específicamente para escenarios de programación con IA. A diferencia de la facturación tradicional por uso (pay-as-you-go), este plan ofrece paquetes fijos de créditos mensuales o anuales. En el plan Lite mensual, por ejemplo, pagas $6 por 4,100,000,000 créditos mensuales y cada mensaje consume créditos según el modelo y la cantidad de tokens procesados.
| Model | Input (Cache Hit) Token | Input (Cache Miss) Token | Output Token |
|---|---|---|---|
| mimo-v2.5-pro | 2.5 Credits | 300 Credits | 600 Credits |
| mimo-v2.5 | 2 Credits | 100 Credits | 200 Credits |
Si usamos la misma referencia de tokens que usamos de mimo-v2.5-pro en OpenCode Go:
| Modelo | Mensajes | Input Tokens | Output Tokens | Cache Read | Cache Write | Costo |
|---|---|---|---|---|---|---|
mimo-v2.5-pro | 2,239 | 3.8M | 729.4K | 161.5M | 0 | $40.89 |
El costo en créditos sería:
| Concepto | Tokens | Credits |
|---|---|---|
| Cache Read (hits) | 161.5M | 403,750,000 |
| Input (misses) | 3.8M | 1,140,000,000 |
| Output | 729.4K | 437,640,000 |
| Total | 1,981,390,000 (~1.98B) |
Serían consumidos 1.98B créditos, lo que en el plan Lite de Xiaomi MiMo equivaldría a 48.32% del paquete mensual de 4.1B créditos por $6.
Si procesáramos todo el consumo de Opencode Go en Xiaomi MiMo, la diferencia entre modelos es notable:
| Concepto | Tokens | mimo-v2.5-pro | mimo-v2.5 |
|---|---|---|---|
| Cache Read | 242.2M | 605.5M credits | 323M credits |
| Input (misses) | 8.3M | 2,476.3M credits | 380M credits |
| Output | 1.6M | 943M credits | 145.9M credits |
| Total | ~4B credits | ~849M credits | |
| % del plan Lite ($6) | 98% | 21% |
Con MiMo-v2.5-pro casi agotamos el plan Lite de 4.1B credits. Con MiMo-v2.5 usamos solo el 21%, y todavía queda margen para mucho más uso.
Con este análisis, creo que conviene combinar OpenCode Go y Xiaomi MiMo Token Plan: usar modelos como Qwen3.7 Max para planificación y Spec Driven Development (SDD), reservar MiMo-v2.5-pro para desarrollo y refactoring, y dejar MiMo-v2.5 para tareas menos críticas. Así se mejora el consumo de créditos y se reducen costos sin sacrificar calidad.
Conclusión
Después de 11 días, 4,550 mensajes y $50.31 en consumo, tengo claro que para uso intensivo y personal, la flexibilidad de modelos importa más que el nombre de la herramienta.
Claude Code es bueno, pero sus planes están pensados para otro patrón de uso, cada vez más restrictivo y enfocado en el uso empresarial. El plan Pro se queda corto en minutos, el Max 5x no alcanza en ventanas de alta actividad, y el Max 20x (el único viable) cuesta $200/mes y te limita al ecosistema de Anthropic.
OpenCode Go con su suscripción de $10 me da acceso a muchos modelos, sin límites rígidos por ventana de tiempo. Cuando supero el tope mensual, OpenCode Zen me permite seguir trabajando con pay-as-you-go y zero markup. Agrego créditos solo cuando los necesito, sin compromisos mensuales.
La combinación con Xiaomi MiMo Token Plan abre otra puerta. Si tu flujo depende mucho de MiMo-v2.5-pro, puedes reducir costos bastante usando su sistema de créditos, reservando OpenCode Go para modelos que MiMo no cubre. Además, recientemente Xiaomi MiMo bajó los precios de sus APIs, lo que hace esta opción aún más atractiva para desarrolladores con consumo alto. Los precios ahora están iguales a Deepseek V4 pero con modelos más potentes.
Mi setup personal actual: OpenCode Go ($10) + Xiaomi MiMo Token Plan. Costo mensual estimado: $16. Cinco veces menos que el plan Max 5x de Claude. Uso Qwen3.7 Max para planificación y Spec Driven Development (SDD), MiMo-v2.5 y MiMo-v2.5-pro para desarrollo y refactoring, y los demás modelos para probar y tener una segunda opinión. Con este setup, no tengo interrupciones por límites de uso, tengo acceso a una variedad de modelos y mantengo un costo controlado.
Para el trabajo profesional, uso la herramienta que mi trabajo me proporciona, sea Claude, Cursor, Codex o cualquier otra. Lo más importante es seguir probando las herramientas y entender cómo ser más eficiente con ellas.
La herramienta perfecta no existe. Lo que importa es cuál se adapta a tu patrón de uso. Si eres de los que codean 8 horas seguidas, delegan tareas a modelos baratos y reservan el premium para lo que importa, los números hablan por sí solos.
Si quieres replicar el análisis, revisa tu consumo. Si pasas los $20/mes, considera una opción pay-as-you-go antes de cambiar de herramienta de golpe.
]]>