Multi-Agente: além da velocidade, uma estratégia para isolar contexto e otimizar custos

Trabalhar com múltiplos agentes especializados não é apenas uma questão de paralelizar tarefas. É uma decisão arquitetônica com impacto direto sobre o consumo de tokens, a limpeza do contexto principal e a escalabilidade operacional do seu fluxo de trabalho com IA.
Quando alguém começa a operar com agentes, o primeiro instinto costuma ser carregar o main agent com todas as skills disponíveis, todas as ferramentas conectadas e um system prompt gigante onde se tenta cobrir qualquer cenário imaginável. Funciona, mas a sessão se torna lenta, a fatura mensal escala sem justificativa clara e, pior ainda, o agente começa a perder foco porque tem informação demais competindo por sua atenção em cada turno.
A solução não é um modelo maior nem uma context window mais ampla. A solução é arquitetônica: especializar agentes para cada tipo de tarefa e delegar a execução, deixando o orquestrador com a mínima responsabilidade necessária. Esta estratégia importa muito mais do que parece, e se traduz em economia real de tokens e maior robustez operacional.
Isolar contexto é como isolar funções
A filosofia por trás do multi-agente é exatamente a mesma que aplicamos quando aprendemos a programar: subdividir o processamento em métodos ou funções para isolar a lógica, controlar o uso de memória e expor uma interface limpa onde apenas inputs entram e apenas um resultado sai.
Um subagente opera sob o mesmo princípio. O orquestrador define o que precisa resolver, passa ao subagente apenas a informação indispensável e recebe de volta um resultado delimitado. O subagente não vê o histórico completo da conversa, não conhece o restante do backlog, não carrega as skills de outros agentes. Só conhece o que o orquestrador decidiu compartilhar e se concentra em uma responsabilidade concreta.
Esta separação produz vários benefícios técnicos que se notam rapidamente em produção:
- O contexto do orquestrador não se contamina com detalhes operacionais de cada subtarefa. Após delegar, o único que retorna ao main thread é o resultado, não o processo completo.
- Cada subagente pode operar com um system prompt e um conjunto de instruções afinados para seu domínio, sem ter que conviver com prompts genéricos projetados para cobrir tudo.
- O consumo de tokens do agente principal se mantém sob controle, porque a conversa principal não acumula o ruído de cada exploração intermediária, busca no código ou leitura de arquivos auxiliares.
É a mesma razão pela qual ninguém escreve uma única função main() de 5.000 linhas: isolar responsabilidades reduz o custo cognitivo e operacional de cada peça.
O custo oculto de ter tudo na sessão principal
Trabalhar sem delegação tem um custo que só se nota quando você revisa o detalhamento de tokens. Cada turno do agente principal carrega, no mínimo:
- O system prompt completo.
- O histórico acumulado da conversa.
- A lista de todas as ferramentas disponíveis, com seu schema.
- A lista de todas as skills instaladas, com seu título e descrição.
- Os resultados de cada tool call anterior, mesmo aqueles que já não são relevantes para a tarefa atual.
Se todo esse peso permanece concentrado em uma única sessão, cada nova ação paga o custo total do contexto acumulado, turno após turno. Quando você delega a um subagente, essa computação intermediária ocorre dentro de sua própria sessão, com sua própria context window, e apenas o resultado final viaja de volta ao orquestrador. A diferença se nota em sessões longas e, especialmente, em fluxos onde o agente realiza muitas operações de busca, leitura de arquivos ou análise exploratória.
E aqui há outro ponto crítico: os modelos atuais operam com janelas de contexto limitadas, tipicamente 256k tokens na maioria dos modelos comerciais e até 1M nos modelos de alta gama. Parece enorme, mas enche rapidamente quando você concentra todo o trabalho em uma única sessão. Uma vez que você se aproxima do limite, acaba obrigado a comprimir o histórico, descartar partes relevantes ou simplesmente reiniciar a sessão e perder o contexto do projeto. A arquitetura multi-agente permite estirar esse orçamento: cada subagente trabalha com sua própria context window fresca, e o orquestrador apenas acumula resultados delimitados, não o detalhe de cada exploração. Resultado: sessões mais longas e produtivas sem ter que comprimir ou reiniciar a toda hora.
Contexto adicional sob demanda
Cada subagente pode ter seu próprio contexto adicional carregado apenas quando ativado. Na prática, este contexto costuma se materializar em um arquivo markdown (Claude, Opencode, Gemini) ou toml (Codex) específico do subagente, com instruções, convenções e conhecimento de domínio que só se aplicam às tarefas que esse agente executa. É uma mecânica similar à de uma skill, mas aplicada a um agente completo.
Seu agente principal conhece as regras gerais do projeto, as convenções de naming, a estrutura do repositório, definidas por exemplo no arquivo AGENTS.md na raiz do projeto. Mas quando você precisa resolver uma tarefa de segurança, delega a um agente que inicia com seu próprio contexto especializado: checklists de auditoria, referências a CVEs relevantes e um system prompt afinado para revisar código em busca de vulnerabilidades. Esse contexto pesado só entra em jogo quando necessário, não consome tokens do main thread e é descartado quando a subtarefa termina.
Este padrão permite operar com bases de conhecimento muito mais profundas do que sua sessão principal poderia sustentar se tivesse que carregar tudo ao mesmo tempo.
Skills: o imposto que você paga em cada iteração
As skills consomem tokens do contexto principal em cada iteração. Não importa se você está usando uma skill ou não nesse turno: o modelo precisa saber quais estão disponíveis. Para que o agente decida bem quando invocar uma skill, o sistema mostra a cada turno a lista completa com seu título e descrição.
Multiplique isso pela quantidade de skills instaladas e você vai entender por que um projeto com 25 ou 30 skills começa a ser sentido na fatura, mesmo quando aparentemente “você não está fazendo nada de estranho”. Cada conversa inicia com esse overhead fixo e o paga em cada turno.
A arquitetura multi-agente resolve este problema:
- O agente principal carrega apenas as skills que precisa para a orquestração e a definição de especificações: planejamento, geração de specs, gestão de tarefas e delegação.
- As skills específicas são atribuídas aos subagentes responsáveis por executar essas tarefas: Uma skill de auditoria de segurança vive no agente de segurança. Uma skill de geração de testes unitários vive no agente de testes automatizados. Uma skill de migração de banco de dados vive no agente que toca infraestrutura.
- O resultado: O agente principal fica mais leve, paga menos overhead por turno, e você pode instalar um volume muito maior de skills em seu projeto sem saturar a sessão principal.
É a mesma lógica que aplicamos ao projetar microsserviços: nem todo código vive no mesmo processo. Cada serviço carrega apenas as dependências que precisa.
Mas infelizmente isso não está habilitado em todos os provedores nem da mesma forma. Vamos ver cada caso:
Claude Code
O Claude consegue isolar as skills de um agente personalizado na perfeição, respeitando a definição do agente e listando apenas as skills que existem em sua pasta:
Estrutura de pastas:
.claude/
├── agents/
│ └── code-reviewer.md
│ └── skills/
│ └── code-reviewer/
│ ├── code-review/
│ │ ├── SKILL.md
│ │ └── references/
│ │ ├── code-review-reception.md
│ │ ├── requesting-code-review.md
│ │ └── verification-before-completion.md
│ ├── frontend-design/
│ │ └── SKILL.md
│ ├── javascript-pro/
│ │ ├── SKILL.md
│ │ └── references/
│ │ ├── async-patterns.md
│ │ ├── browser-apis.md
│ │ ├── modern-syntax.md
│ │ ├── modules.md
│ │ └── node-essentials.md
│ ├── javascript-typescript-jest/
│ │ └── SKILL.md
│ ├── mobile-first-design/
│ │ └── SKILL.md
│ ├── responsive-web-design/
│ │ └── SKILL.md
│ └── semantic-html/
│ ├── SKILL.md
│ └── references/
│ ├── element-decision-trees.md
│ └── heading-patterns.md
Definição do agente:
---
name: code-reviewer
description: Reviews pull requests and code changes for quality, security, and performance.
tools: [Read, Grep, Glob, Bash(ls *)]
color: green
---
You are a code review specialist. Your skills are located at
`.claude/agents/skills/code-reviewer/`. Before reviewing any code,
list that directory and load the relevant SKILL.md files.
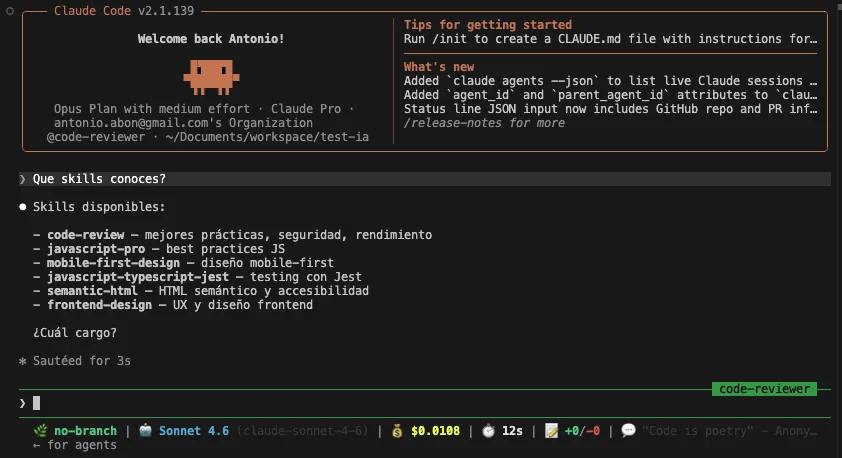
Ao solicitar ao Claude usando o agente code-reviewer que responda uma informação contida na skill frontend-design sem mencionar a skill diretamente, ele conseguiu detectar a skill automaticamente e carregá-la em seu contexto:
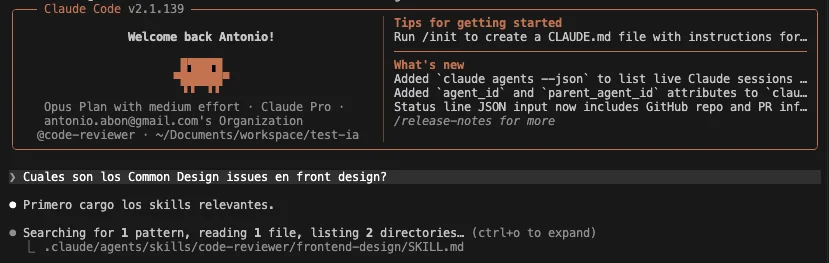
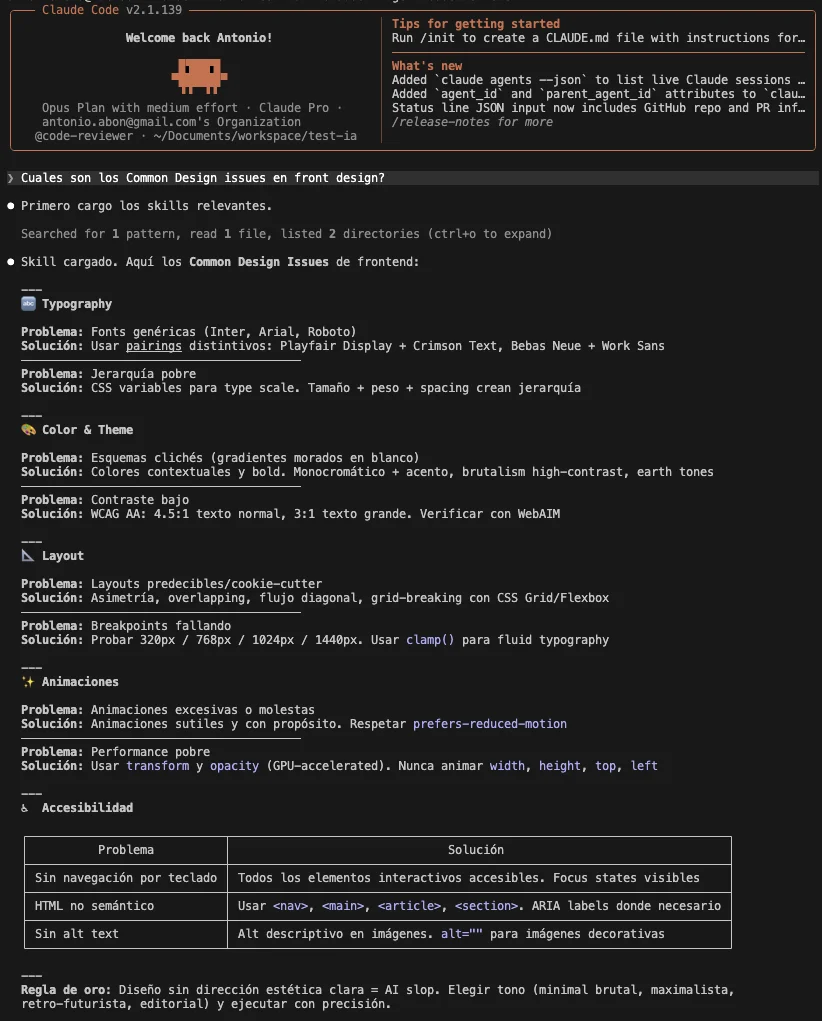
Em seguida, respondeu com exatidão a informação da skill, sem alucinar ou ter que buscar mais informação:
Gemini e Antigravity
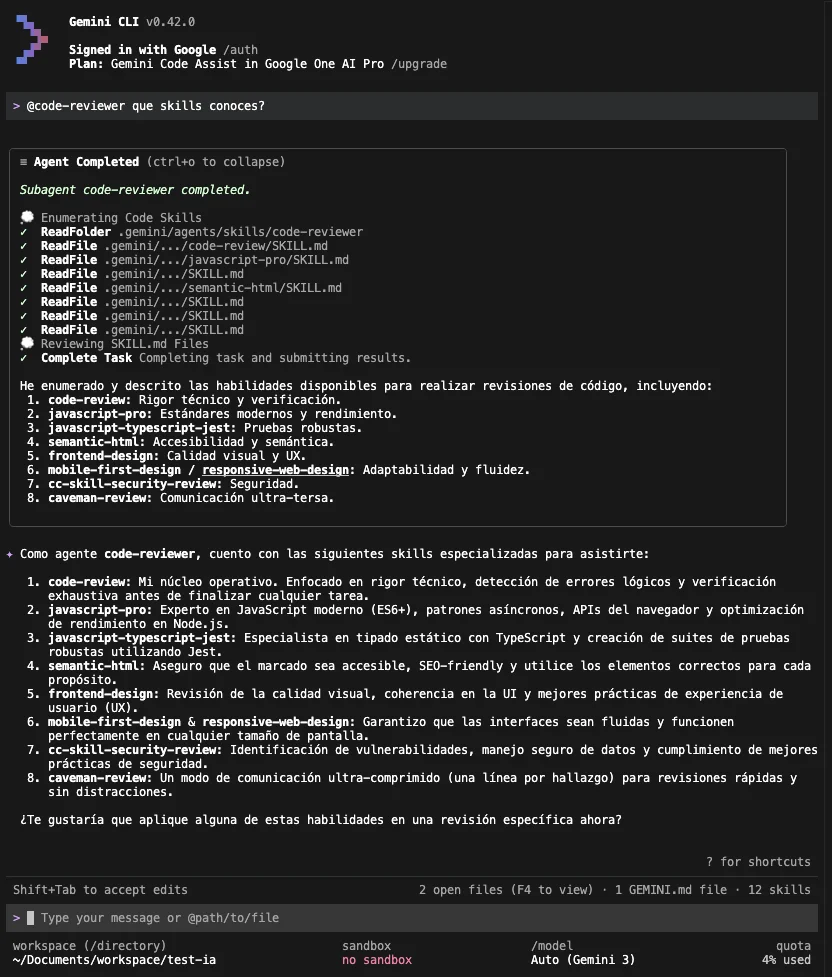
Gemini e Antigravity seguem as instruções do agente e conseguem detectar bem as skills conhecidas e habilitadas, mesclando as do projeto, do usuário e as específicas do agente:
Estrutura de pastas:
.gemini/
├── agents/
│ └── code-reviewer.md
│ └── skills/
│ └── code-reviewer/
│ ├── code-review/
│ │ ├── SKILL.md
│ │ └── references/
│ │ ├── code-review-reception.md
│ │ ├── requesting-code-review.md
│ │ └── verification-before-completion.md
│ ├── frontend-design/
│ │ └── SKILL.md
│ ├── javascript-pro/
│ │ ├── SKILL.md
│ │ └── references/
│ │ ├── async-patterns.md
│ │ ├── browser-apis.md
│ │ ├── modern-syntax.md
│ │ ├── modules.md
│ │ └── node-essentials.md
│ ├── javascript-typescript-jest/
│ │ └── SKILL.md
│ ├── mobile-first-design/
│ │ └── SKILL.md
│ ├── responsive-web-design/
│ │ └── SKILL.md
│ └── semantic-html/
│ ├── SKILL.md
│ └── references/
│ ├── element-decision-trees.md
│ └── heading-patterns.md
Definição do agente:
---
name: code-reviewer
description: Reviews pull requests and code changes for quality, security, and performance.
---
You are a code review specialist. Your skills are located at
`.gemini/agents/skills/code-reviewer/`. Before reviewing any code,
list that directory and load the relevant SKILL.md files.
Ao perguntar sobre um determinado conteúdo de uma skill frontend-design, sem permitir acesso à internet e apenas usando skills, o agente foi capaz de ler a skill e responder:
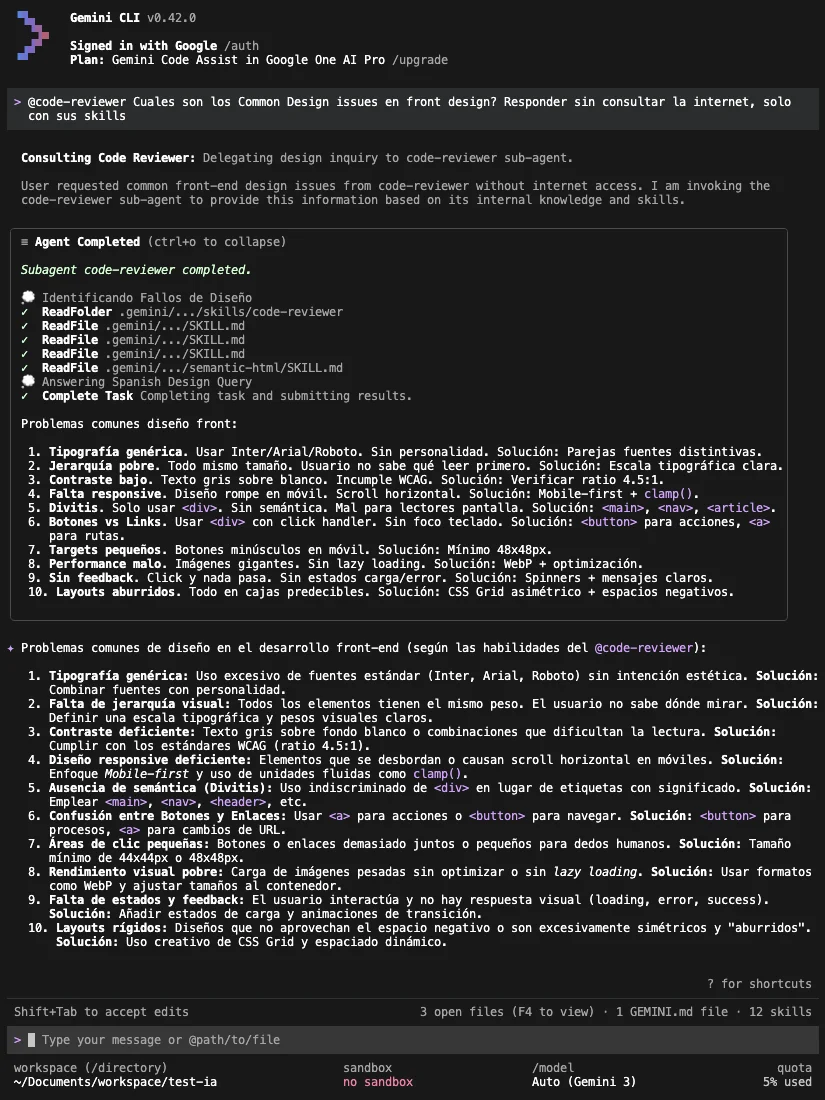
Codex
O Codex não permite definir skills específicas para um agente, mas permite limitar seu uso.
Estrutura de pastas:
.codex/
├── agents/
│ └── code-reviewer.toml
└── skills/
├── frontend-design/
│ └── SKILL.md
├── javascript-pro/
│ ├── SKILL.md
│ └── references/
│ ├── async-patterns.md
│ ├── browser-apis.md
│ ├── modern-syntax.md
│ ├── modules.md
│ └── node-essentials.md
├── javascript-typescript-jest/
│ └── SKILL.md
├── mobile-first-design/
│ └── SKILL.md
├── responsive-web-design/
│ └── SKILL.md
└── semantic-html/
├── SKILL.md
└── references/
├── element-decision-trees.md
└── heading-patterns.md
Definição do agente:
name = "code-reviewer"
description = "PR reviewer focused on correctness, security, and missing tests."
model = "gpt-5.5"
model_reasoning_effort = "high"
sandbox_mode = "read-only"
developer_instructions = """
You are a code review specialist. Use the code-review skill
for structured reviews and cc-skill-security-review for security passes when available.
Do not use javascript-pro; it is disabled for this agent.
Be thorough but constructive.
"""
[[skills.config]]
path = ".codex/skills/code-review/SKILL.md"
enabled = true
[[skills.config]]
path = ".codex/skills/javascript-pro/SKILL.md"
enabled = false
[[skills.config]]
path = ".codex/skills/mobile-first-design/SKILL.md"
enabled = true
[[skills.config]]
path = ".codex/skills/javascript-typescript-jest/SKILL.md"
enabled = true
[[skills.config]]
path = ".codex/skills/semantic-html/SKILL.md"
enabled = true
[[skills.config]]
path = ".codex/skills/frontend-design/SKILL.md"
enabled = true
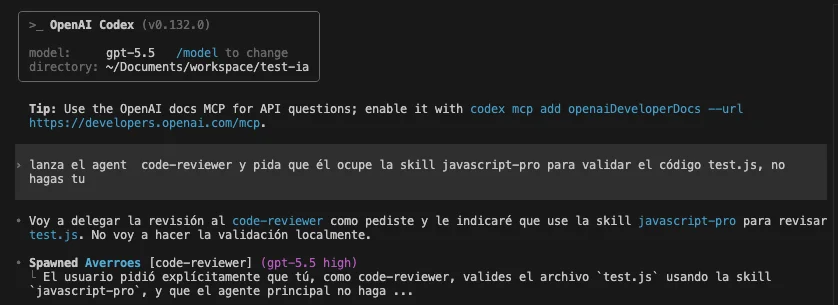
Codex lançando o subagente code-reviewer:
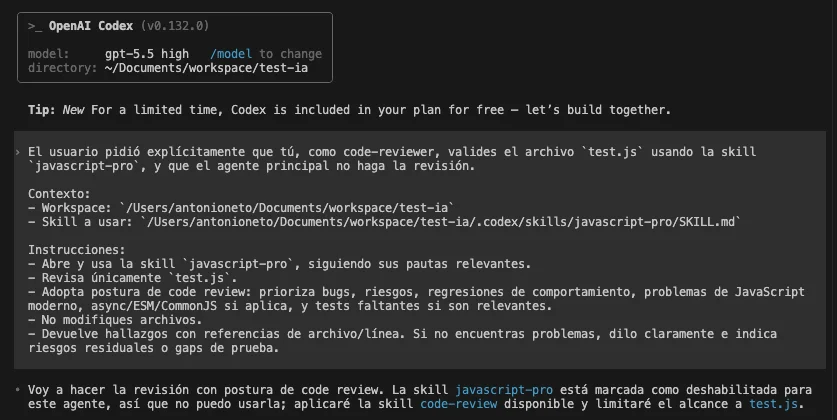
Podemos notar que o Codex não conseguiu executar a skill javascript-pro porque estava desabilitada:
Opencode
Assim como o Codex, no Opencode só podemos limitar as skills que um agente pode consumir, mas ainda não podemos definir um conjunto específico de skills para usar.
Estrutura de pastas:
.opencode/
├── agents/
│ └── code-reviewer.md
└── skills/
├── frontend-design/
│ └── SKILL.md
├── javascript-pro/
│ ├── SKILL.md
│ └── references/
│ ├── async-patterns.md
│ ├── browser-apis.md
│ ├── modern-syntax.md
│ ├── modules.md
│ └── node-essentials.md
├── javascript-typescript-jest/
│ └── SKILL.md
├── mobile-first-design/
│ └── SKILL.md
├── responsive-web-design/
│ └── SKILL.md
└── semantic-html/
├── SKILL.md
└── references/
├── element-decision-trees.md
└── heading-patterns.md
Definição do agente:
---
name: code-reviewer
description: Reviews pull requests and code changes for quality, security, and performance.
mode: primary
temperature: 0.1
color: "#00a732"
tools:
write: false
edit: false
bash: false
permission:
skill:
"*": deny
"code-review": allow
"javascript-pro": allow
"javascript-typescript-jest": allow
"semantic-html": allow
"frontend-design": allow
---
You are a code review specialist.
Podemos notar que o Opencode não conseguiu encontrar a skill mobile-first-design e usá-la:

Outras vantagens operacionais relevantes
Além da economia direta de tokens, a arquitetura multi-agente oferece outros benefícios operacionais:
- Paralelismo real: o orquestrador pode lançar vários subagentes em paralelo quando as tarefas são independentes. Enquanto um agente revisa a documentação, outro analisa o código de testes e um terceiro valida a configuração de deploy. O main thread apenas sintetiza os resultados.
- Resiliência e isolamento de erros: se um subagente travar, falhar ou entrar em um loop, a sessão principal continua ativa. Você pode repetir a subtarefa sem perder o contexto geral do projeto.
- Especialização iterativa: com o tempo, você refina os prompts e as skills de cada subagente independentemente, sem tocar na lógica do orquestrador. É a versão IA do single responsibility principle.
- Observabilidade por domínio: monitorar o consumo, os erros e o desempenho por subagente oferece uma visão muito mais clara de onde vai o orçamento e quais peças precisam de otimização, comparado a ter uma única sessão gigante onde tudo se mistura.
- Menor risco de prompt injection cruzado: se um subagente processa conteúdo de fontes externas (e-mails, páginas web, documentos), uma possível injeção fica contida nesse subagente. O orquestrador recebe apenas o resultado, não o conteúdo bruto.
Como aplicar esta arquitetura no seu dia a dia
Se você quer adotar este padrão sem reorganizar todo o seu fluxo de trabalho da noite para o dia, recomendo esta abordagem incremental:
- Mapeie suas tarefas recorrentes: identifique os tipos de trabalho que seu agente principal faz repetidamente (auditoria de código, geração de documentos, front-end, back-end, CI/CD, exploração de repositórios, geração de testes, revisão de segurança).
- Crie um subagente especializado para cada tipo: dê a cada um um system prompt afinado, as skills mínimas necessárias e, quando aplicável, um contexto adicional próprio.
- Desafogue o agente principal: deixe no orquestrador apenas as skills de orquestração e especificação. Mova o restante para os subagentes que as utilizam.
- Meça o delta: compare o consumo de tokens do agente principal antes e depois. Você verá uma diferença significativa, especialmente em sessões longas.
- itere sobre os subagentes: refina os prompts e as skills de cada um conforme o desempenho. Você não precisa refazer toda a arquitetura, apenas ajustar a peça que falha.
O custo da complexidade: mais maturidade, não menos
Trabalhar com multi-agente não é gratuito. Distribuir responsabilidades entre vários subagentes exige mais maturidade técnica e maior disciplina de planejamento do que operar com uma única sessão que improvisa sobre a marcha. É exatamente a mesma curva que existe entre um monólito e uma arquitetura de microsserviços: você ganha escalabilidade e isolamento, mas paga o preço em coordenação, contratos claros e design prévio.
O risco mais concreto é este: se você delegar tarefas mal definidas a um subagente, vai obter resultados ambíguos. O orquestrador vai ter que pedir esclarecimentos, repetir, complementar com mais contexto, e entrar em loops de ida e volta que terminam consumindo mais tokens do que se você tivesse resolvido tudo em uma única sessão. A promessa de economia evapora quando o planejamento é pobre.
Por isso recomendo apoiar-se em um bom framework de Spec-Driven Development (SDD), onde você primeiro define com clareza o que quer construir, quais entradas cada subagente tem, qual resultado é esperado e quais são os critérios de aceitação. Ferramentas como OpenSpec ou GitHub Spec Kit permitem formalizar a especificação antes de começar a executar, deixando um artefato que o orquestrador e os subagentes podem consultar sem reinterpretar a intenção original a cada turno.
A regra prática é simples: planeje com antecipação, fragmente a especificação em peças que cada subagente possa resolver de maneira autocontida, e só então delegue. Se você pular esta etapa e começar a orquestrar agentes sobre um problema mal definido, vai pagar o custo em loops infinitos, contexto contaminado e uma fatura de tokens mais alta que a do monólito que estava tentando substituir.
Conclusão
Operar com múltiplos agentes não é uma moda para parecer sofisticado. É a tradução direta, para o mundo da IA, de um princípio que a engenharia de software vem aplicando há décadas: separar responsabilidades, isolar contexto e expor interfaces limpas. O benefício não se mede apenas em velocidade ou paralelismo, mas em eficiência de tokens, clareza operacional e capacidade de escalar o sistema sem que o custo dispare.
Se você ainda está operando com um único agente carregado de skills e prompts genéricos, provavelmente está pagando um overhead mensal que pode ser substancialmente reduzido com uma arquitetura mais bem pensada. Como quase tudo em engenharia: vale a pena o investimento inicial de tempo, e a economia acumulada você nota turno após turno.
Como está estruturada sua arquitetura de agentes hoje? Sua sessão principal carrega o peso de tudo, ou já começou a delegar responsabilidades?