Multi-Agente: más allá de la velocidad, una estrategia para aislar contexto y optimizar costos

Trabajar con múltiples agentes especializados no es solo una cuestión de paralelizar tareas. Es una decisión arquitectónica con impacto directo sobre el consumo de tokens, la limpieza del contexto principal y la escalabilidad operativa de tu flujo de trabajo con IA.
Cuando alguien empieza a operar con agentes, el primer instinto suele ser cargar al main agent con todas las skills disponibles, todas las herramientas conectadas y un system prompt gigante donde se intenta cubrir cualquier escenario imaginable. Funciona, pero la sesión se vuelve lenta, la factura mensual escala sin justificación clara y, lo peor, el agente empieza a perder foco porque tiene demasiada información compitiendo por su atención en cada turno.
La solución no es un modelo más grande ni un context window más amplio. La solución es arquitectónica: especializar agentes para cada tipo de tarea y delegar la ejecución, dejando al orquestador con la mínima responsabilidad necesaria. Esta estrategia importa mucho más de lo que parece, y se traduce en ahorro real de tokens y mayor robustez operativa.
Aislar contexto es como aislar funciones
La filosofía detrás del multi-agente es exactamente la misma que aplicamos cuando aprendimos a programar: subdividir el procesamiento en métodos o funciones para aislar la lógica, controlar el uso de memoria y exponer una interfaz limpia donde solo entran inputs y solo sale un resultado.
Un subagente opera bajo el mismo principio. El orquestador define qué necesita resolver, le pasa al subagente únicamente la información indispensable y recibe de vuelta un resultado acotado. El subagente no ve el historial completo de la conversación, no conoce el resto del backlog, no carga las skills de otros agentes. Solo conoce lo que el orquestador decidió compartir y se enfoca en una responsabilidad concreta.
Esta separación produce varios beneficios técnicos que se notan rápido en producción:
- El contexto del orquestador no se contamina con detalles operativos de cada subtarea. Después de delegar, lo único que vuelve al main thread es el resultado, no el proceso completo.
- Cada subagente puede operar con un system prompt y un conjunto de instrucciones afinados para su dominio, sin tener que convivir con prompts genéricos diseñados para cubrir todo.
- El consumo de tokens del agente principal se mantiene bajo control, porque la conversación principal no acumula el ruido de cada exploración intermedia, búsqueda en el código o lectura de archivos auxiliares.
Es la misma razón por la cual nadie escribe una sola función main() de 5.000 líneas: aislar responsabilidades reduce el costo cognitivo y operativo de cada pieza.
El costo oculto de tener todo en la sesión principal
Trabajar sin delegación tiene un costo que solo se nota cuando revisas el desglose de tokens. Cada turno del agente principal carga, como mínimo:
- El system prompt completo.
- El historial acumulado de la conversación.
- La lista de todas las herramientas disponibles, con su schema.
- La lista de todas las skills instaladas, con su título y descripción.
- Los resultados de cada tool call previa, incluso aquellos que ya no son relevantes para la tarea actual.
Si todo este peso permanece concentrado en una sola sesión, cada nueva acción paga el costo total del contexto acumulado, turno tras turno. Cuando delegas a un subagente, ese cómputo intermedio ocurre dentro de su propia sesión, con su propio context window, y solo el resultado final viaja de vuelta al orquestador. La diferencia se nota en sesiones largas y, sobre todo, en flujos donde el agente realiza muchas operaciones de búsqueda, lectura de archivos o análisis exploratorio.
Y acá hay otro punto crítico: los modelos actuales operan con ventanas de contexto limitadas, típicamente 256k tokens en la mayoría de modelos comerciales y hasta 1M en los modelos de gama alta. Suena enorme, pero se llena rápido cuando concentras todo el trabajo en una sola sesión. Una vez que te acercas al límite, terminas obligado a comprimir el historial, descartar partes relevantes o directamente reiniciar la sesión y perder el contexto del proyecto. La arquitectura multi-agente te permite estirar ese presupuesto: cada subagente trabaja con su propio context window fresco, y el orquestador solo acumula resultados acotados, no el detalle de cada exploración. Resultado: sesiones más largas y productivas sin tener que comprimir o reiniciar a cada rato.
Contexto adicional bajo demanda
Cada subagente puede tener su propio contexto adicional cargado únicamente cuando se activa. En la práctica, este contexto suele materializarse en un archivo markdown (Claude, Opencode, Gemini) o toml (Codex) específico del subagente, con instrucciones, convenciones y conocimiento de dominio que solo aplican a las tareas que ese agente ejecuta. Es una mecánica similar a la de una skill, pero aplicada a un agente completo.
Tu agente principal conoce las reglas generales del proyecto, las convenciones de naming, la estructura del repositorio, definidas por ejemplo en el archivo AGENTS.md en la raíz del proyecto. Pero cuando necesitas resolver una tarea de seguridad, delegas a un agente que arranca con su propio contexto especializado: checklists de auditoría, referencias a CVEs relevantes y un system prompt afinado para revisar código en busca de vulnerabilidades. Ese contexto pesado solo entra en juego cuando hace falta, no consume tokens del main thread y se descarta cuando la subtarea termina.
Este patrón te permite operar con bases de conocimiento mucho más profundas de lo que tu sesión principal podría sostener si tuviera que cargar todo al mismo tiempo.
Skills: el impuesto que pagas en cada iteración
Las skills consumen tokens del contexto principal en cada iteración. No importa si estás usando una skill o no en ese turno: el modelo necesita saber cuáles tiene disponibles. Para que el agente decida bien cuándo invocar una skill, el sistema le muestra en cada turno la lista completa con su título y descripción.
Multiplica eso por la cantidad de skills instaladas y vas a entender por qué un proyecto con 25 o 30 skills empieza a notarse en la factura, incluso cuando aparentemente “no estás haciendo nada raro”. Cada conversación arranca con ese overhead fijo y lo paga en cada turno.
La arquitectura multi-agente resuelve este problema:
- El agente principal solo carga las skills que necesita para la orquestación y la definición de especificaciones: planificación, generación de specs, gestión de tareas y delegación.
- Las skills específicas se asignan a los subagentes responsables de ejecutar esas tareas: Una skill de auditoría de seguridad vive en el agente de seguridad. Una skill de generación de tests unitarios vive en el agente de pruebas automatizadas. Una skill de migración de bases de datos vive en el agente que toca infraestructura.
- El resultado: El agente principal queda más liviano, paga menos overhead por turno, y puedes instalar un volumen mucho mayor de skills en tu proyecto sin saturar la sesión principal.
Es la misma lógica que aplicamos al diseñar microservicios: no todo el código vive en el mismo proceso. Cada servicio carga solo las dependencias que necesita.
Pero lamentablemente esto no está habilitado en todos los proveedores ni de la misma forma. Veamos cada caso:
Claude Code
Claude logra aislar las skills de un agente personalizado a la perfección, respetando la definición del agente y listando solamente las skills que existen en su carpeta:
Estructura de carpetas:
.claude/
├── agents/
│ └── code-reviewer.md
│ └── skills/
│ └── code-reviewer/
│ ├── code-review/
│ │ ├── SKILL.md
│ │ └── references/
│ │ ├── code-review-reception.md
│ │ ├── requesting-code-review.md
│ │ └── verification-before-completion.md
│ ├── frontend-design/
│ │ └── SKILL.md
│ ├── javascript-pro/
│ │ ├── SKILL.md
│ │ └── references/
│ │ ├── async-patterns.md
│ │ ├── browser-apis.md
│ │ ├── modern-syntax.md
│ │ ├── modules.md
│ │ └── node-essentials.md
│ ├── javascript-typescript-jest/
│ │ └── SKILL.md
│ ├── mobile-first-design/
│ │ └── SKILL.md
│ ├── responsive-web-design/
│ │ └── SKILL.md
│ └── semantic-html/
│ ├── SKILL.md
│ └── references/
│ ├── element-decision-trees.md
│ └── heading-patterns.md
Definición del agente:
---
name: code-reviewer
description: Reviews pull requests and code changes for quality, security, and performance.
tools: [Read, Grep, Glob, Bash(ls *)]
color: green
---
You are a code review specialist. Your skills are located at
`.claude/agents/skills/code-reviewer/`. Before reviewing any code,
list that directory and load the relevant SKILL.md files.
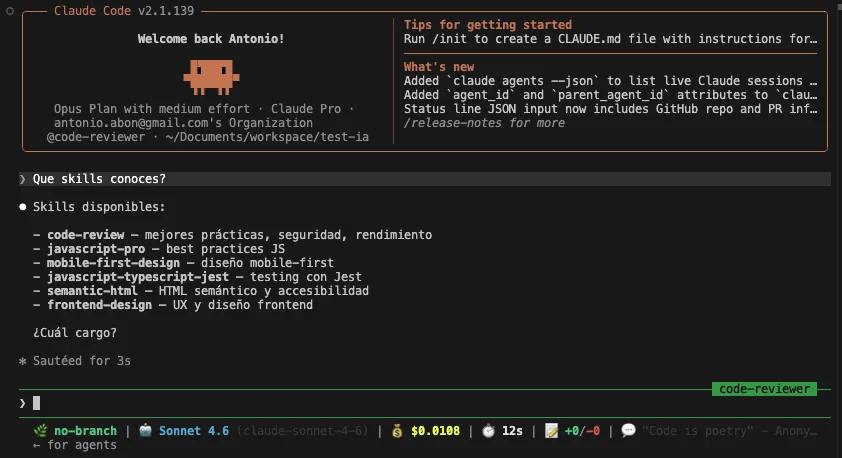
Al solicitar a Claude usando el agente code-reviewer que me responda una información contenida en la skill frontend-design sin mencionar la skill directamente, él logró detectar la skill automáticamente y cargarla en su contexto:
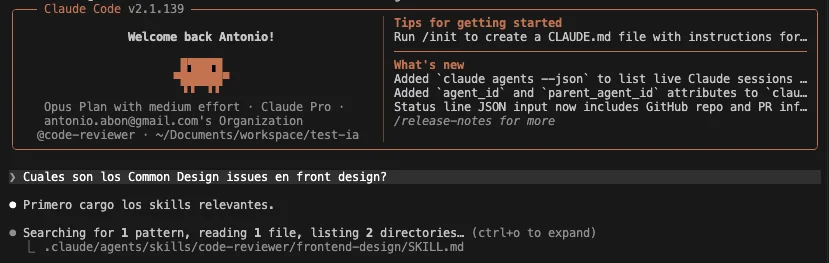
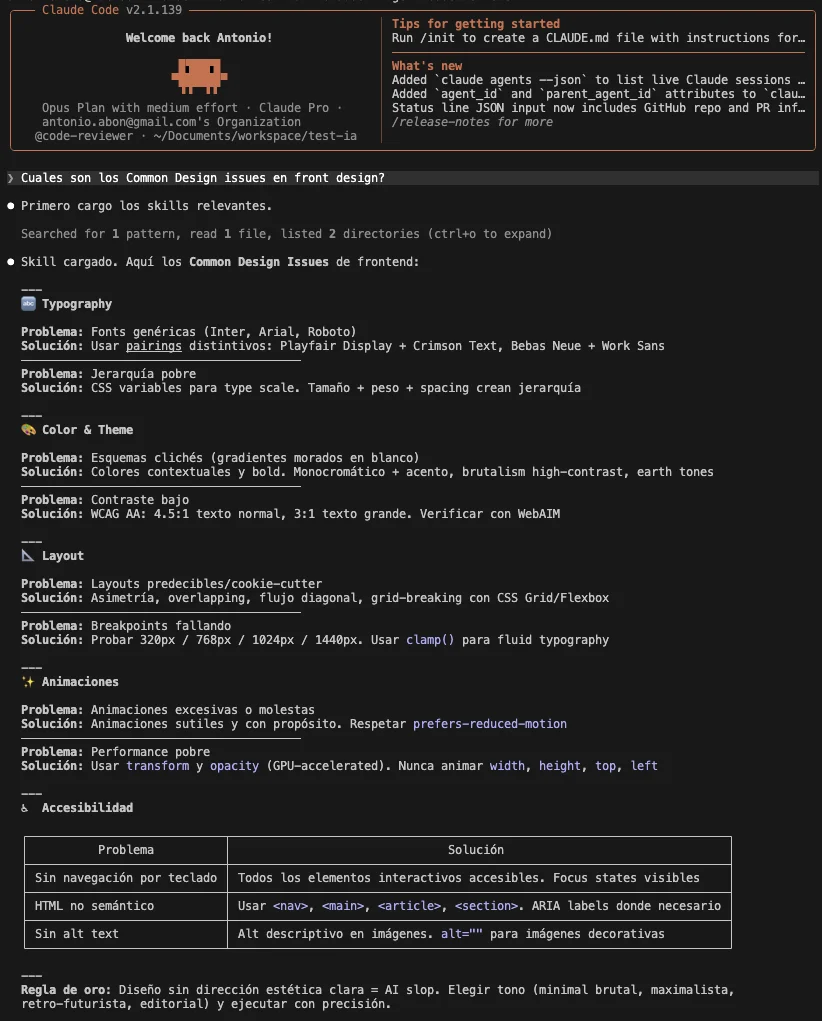
Luego me respondió con exactitud la información de la skill, sin alucinar o tener que buscar más información:
Gemini y Antigravity
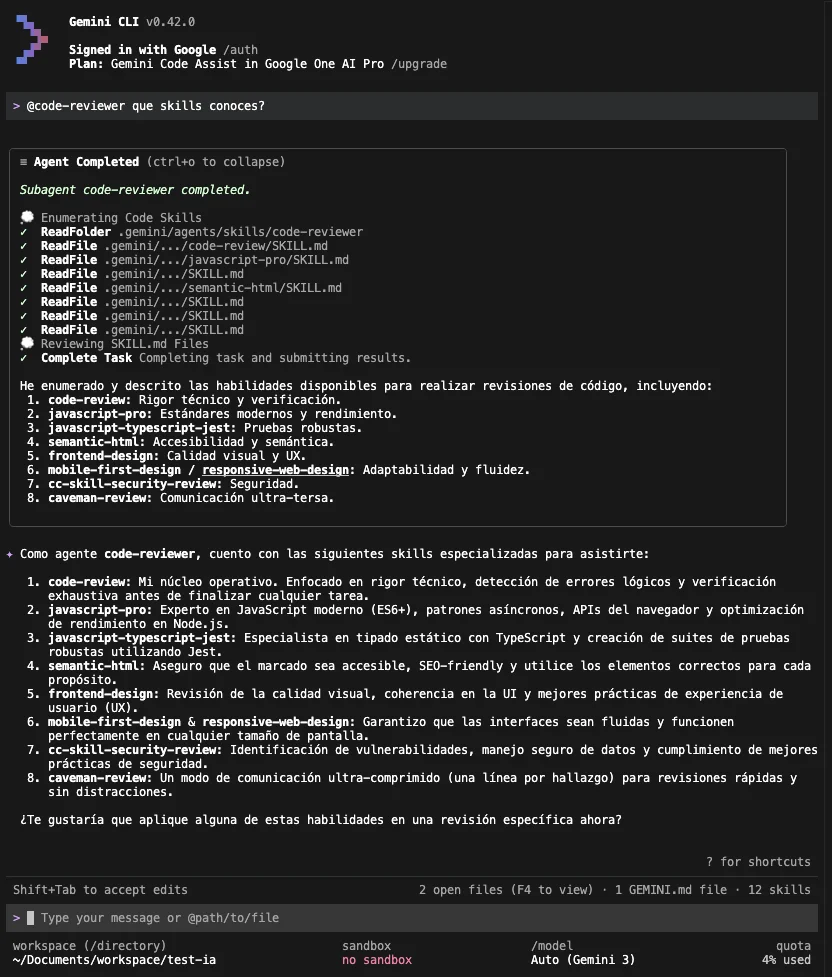
Gemini y Antigravity siguen las instrucciones del agente y logran detectar bien las skills conocidas y habilitadas, mezclando las del proyecto, del usuario y las específicas del agente:
Estructura de carpetas:
.gemini/
├── agents/
│ └── code-reviewer.md
│ └── skills/
│ └── code-reviewer/
│ ├── code-review/
│ │ ├── SKILL.md
│ │ └── references/
│ │ ├── code-review-reception.md
│ │ ├── requesting-code-review.md
│ │ └── verification-before-completion.md
│ ├── frontend-design/
│ │ └── SKILL.md
│ ├── javascript-pro/
│ │ ├── SKILL.md
│ │ └── references/
│ │ ├── async-patterns.md
│ │ ├── browser-apis.md
│ │ ├── modern-syntax.md
│ │ ├── modules.md
│ │ └── node-essentials.md
│ ├── javascript-typescript-jest/
│ │ └── SKILL.md
│ ├── mobile-first-design/
│ │ └── SKILL.md
│ ├── responsive-web-design/
│ │ └── SKILL.md
│ └── semantic-html/
│ ├── SKILL.md
│ └── references/
│ ├── element-decision-trees.md
│ └── heading-patterns.md
Definición del agente:
---
name: code-reviewer
description: Reviews pull requests and code changes for quality, security, and performance.
---
You are a code review specialist. Your skills are located at
`.gemini/agents/skills/code-reviewer/`. Before reviewing any code,
list that directory and load the relevant SKILL.md files.
Al preguntar por un determinado contenido de una skill frontend-design, sin permitir acceso a internet y solamente usando skills, el agente fue capaz de leer la skill y responder:
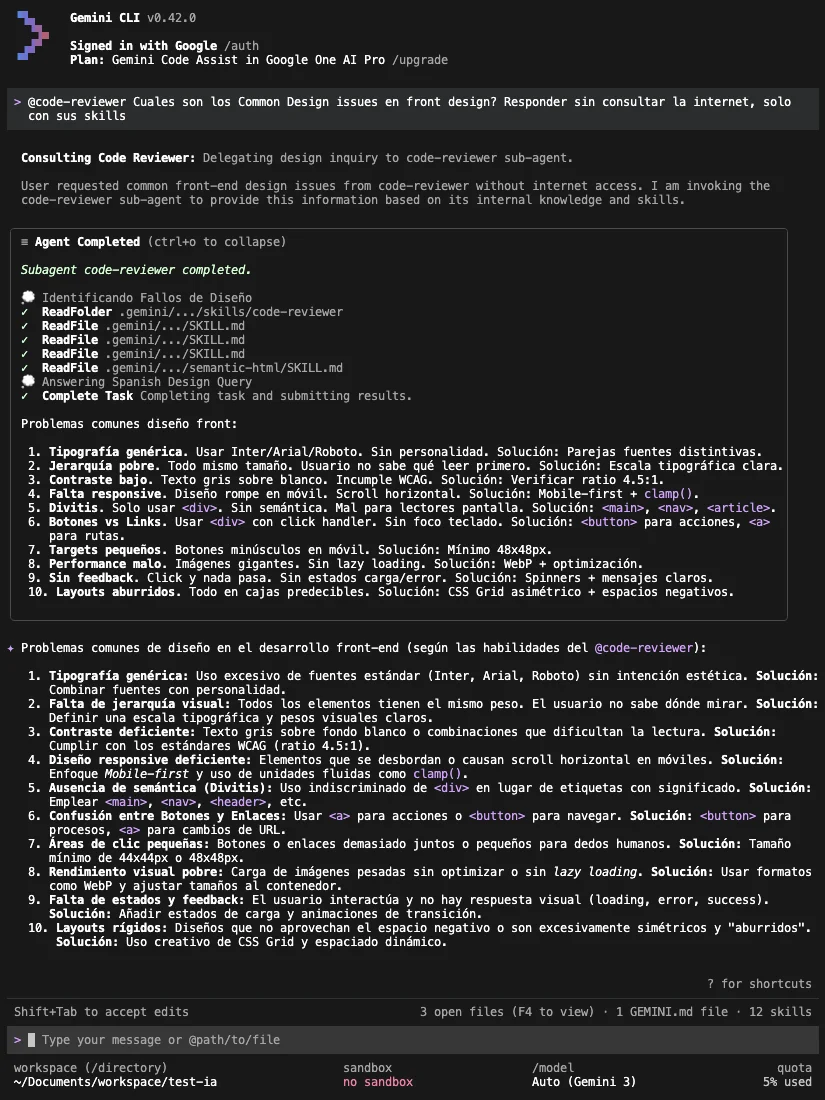
Codex
Codex no permite definir skills específicas para un agente, pero sí limitar su uso.
Estructura de carpetas:
.codex/
├── agents/
│ └── code-reviewer.toml
└── skills/
├── frontend-design/
│ └── SKILL.md
├── javascript-pro/
│ ├── SKILL.md
│ └── references/
│ ├── async-patterns.md
│ ├── browser-apis.md
│ ├── modern-syntax.md
│ ├── modules.md
│ └── node-essentials.md
├── javascript-typescript-jest/
│ └── SKILL.md
├── mobile-first-design/
│ └── SKILL.md
├── responsive-web-design/
│ └── SKILL.md
└── semantic-html/
├── SKILL.md
└── references/
├── element-decision-trees.md
└── heading-patterns.md
Definición del agente:
name = "code-reviewer"
description = "PR reviewer focused on correctness, security, and missing tests."
model = "gpt-5.5"
model_reasoning_effort = "high"
sandbox_mode = "read-only"
developer_instructions = """
You are a code review specialist. Use the code-review skill
for structured reviews and cc-skill-security-review for security passes when available.
Do not use javascript-pro; it is disabled for this agent.
Be thorough but constructive.
"""
[[skills.config]]
path = ".codex/skills/code-review/SKILL.md"
enabled = true
[[skills.config]]
path = ".codex/skills/javascript-pro/SKILL.md"
enabled = false
[[skills.config]]
path = ".codex/skills/mobile-first-design/SKILL.md"
enabled = true
[[skills.config]]
path = ".codex/skills/javascript-typescript-jest/SKILL.md"
enabled = true
[[skills.config]]
path = ".codex/skills/semantic-html/SKILL.md"
enabled = true
[[skills.config]]
path = ".codex/skills/frontend-design/SKILL.md"
enabled = true
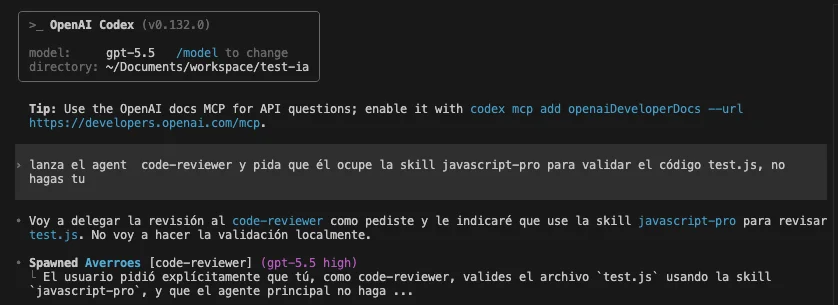
Codex lanzando el subagente code-reviewer:
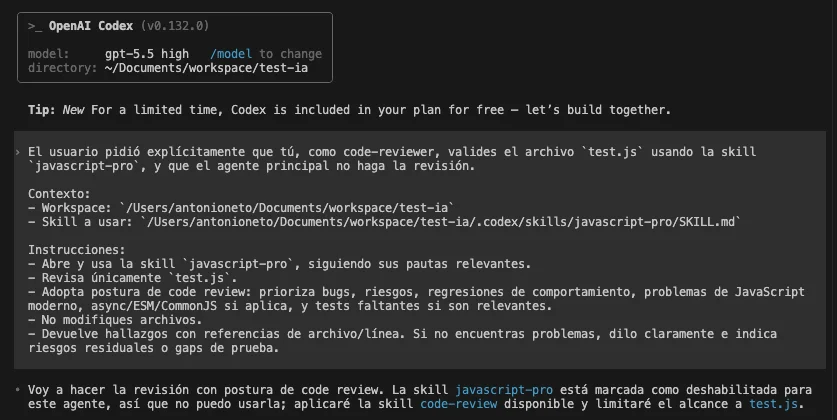
Podemos notar que Codex no pudo ejecutar la skill javascript-pro porque estaba deshabilitada:
Opencode
Así como Codex, en Opencode solo podemos limitar las skills que un agente puede consumir, pero todavía no podemos definir un conjunto de skills específicas para usar.
Estructura de carpetas:
.opencode/
├── agents/
│ └── code-reviewer.md
└── skills/
├── frontend-design/
│ └── SKILL.md
├── javascript-pro/
│ ├── SKILL.md
│ └── references/
│ ├── async-patterns.md
│ ├── browser-apis.md
│ ├── modern-syntax.md
│ ├── modules.md
│ └── node-essentials.md
├── javascript-typescript-jest/
│ └── SKILL.md
├── mobile-first-design/
│ └── SKILL.md
├── responsive-web-design/
│ └── SKILL.md
└── semantic-html/
├── SKILL.md
└── references/
├── element-decision-trees.md
└── heading-patterns.md
Definición del agente:
---
name: code-reviewer
description: Reviews pull requests and code changes for quality, security, and performance.
mode: primary
temperature: 0.1
color: "#00a732"
tools:
write: false
edit: false
bash: false
permission:
skill:
"*": deny
"code-review": allow
"javascript-pro": allow
"javascript-typescript-jest": allow
"semantic-html": allow
"frontend-design": allow
---
You are a code review specialist.
Podemos notar que Opencode no logró encontrar la skill mobile-first-design y usarla:

Otras ventajas operativas relevantes
Además del ahorro directo de tokens, la arquitectura multi-agente ofrece otros beneficios operativos:
- Paralelismo real: el orquestador puede lanzar varios subagentes en paralelo cuando las tareas son independientes. Mientras un agente revisa la documentación, otro analiza el código de pruebas y un tercero valida la configuración de despliegue. El main thread solo sintetiza los resultados.
- Resiliencia y aislamiento de errores: si un subagente se atasca, falla o entra en un loop, la sesión principal sigue viva. Puedes reintentar la subtarea sin perder el contexto general del proyecto.
- Especialización iterativa: con el tiempo, refinas los prompts y las skills de cada subagente independientemente, sin tocar la lógica del orquestador. Es la versión IA del single responsibility principle.
- Observabilidad por dominio: monitorear el consumo, los errores y el desempeño por subagente te da una visión mucho más clara de dónde se va el presupuesto y qué piezas necesitan optimización, comparado con tener una sola sesión gigante donde todo se mezcla.
- Menor riesgo de prompt injection cruzado: si un subagente procesa contenido de fuentes externas (correos, páginas web, documentos), una posible inyección queda contenida en ese subagente. El orquestador recibe solo el resultado, no el contenido bruto.
Cómo aplicar esta arquitectura en tu día a día
Si quieres adoptar este patrón sin reorganizar todo tu flujo de trabajo de un día para el otro, te recomiendo este enfoque incremental:
- Mapea tus tareas recurrentes: identifica los tipos de trabajo que tu agente principal hace una y otra vez (auditoría de código, generación de documentos, front-end, back-end, CI/CD, exploración de repositorios, generación de tests, revisión de seguridad).
- Crea un subagente especializado por cada tipo: dale a cada uno un system prompt afinado, las skills mínimas necesarias y, cuando aplique, un contexto adicional propio.
- Despeja el agente principal: deja en el orquestador solo las skills de orquestación y especificación. Mueve el resto a los subagentes que las usen.
- Mide el delta: compara el consumo de tokens del agente principal antes y después. Vas a ver una diferencia significativa, especialmente en sesiones largas.
- Itera sobre los subagentes: refina los prompts y las skills de cada uno según el desempeño. No tienes que rehacer toda la arquitectura, solo ajustar la pieza que falla.
El costo de la complejidad: más madurez, no menos
Trabajar con multi-agente no es gratis. Distribuir responsabilidades entre varios subagentes exige más madurez técnica y mayor disciplina de planificación que operar con una sola sesión que improvisa sobre la marcha. Es exactamente la misma curva que existe entre un monolito y una arquitectura de microservicios: ganas escalabilidad y aislamiento, pero pagas el precio en coordinación, contratos claros y diseño previo.
El riesgo más concreto es este: si delegas tareas mal definidas a un subagente, vas a obtener resultados ambiguos. El orquestador va a tener que pedir aclaraciones, reintentar, complementar con más contexto, y entrar en loops de ida y vuelta que terminan consumiendo más tokens que si hubieras resuelto todo en una sola sesión. La promesa de ahorro se evapora cuando la planificación es pobre.
Por eso recomiendo apoyarse en un buen framework de Spec-Driven Development (SDD), donde primero defines con claridad qué quieres construir, qué entradas tiene cada subagente, qué resultado se espera y cuáles son los criterios de aceptación. Herramientas como OpenSpec o GitHub Spec Kit te permiten formalizar la especificación antes de empezar a ejecutar, dejando un artefacto que el orquestador y los subagentes pueden consultar sin reinterpretar la intención original en cada turno.
La regla práctica es simple: planifica con anticipación, fragmenta la especificación en piezas que cada subagente pueda resolver de manera autocontenida, y solo después delega. Si te saltas este paso y empiezas a orquestar agentes sobre un problema mal definido, vas a pagar el costo en loops infinitos, contexto contaminado y una factura de tokens más alta que la del monolito que estabas intentando reemplazar.
Conclusión
Operar con múltiples agentes no es una moda para parecer sofisticado. Es la traducción directa, al mundo de la IA, de un principio que la ingeniería de software lleva décadas aplicando: separar responsabilidades, aislar contexto y exponer interfaces limpias. El beneficio no se mide solo en velocidad o paralelismo, sino en eficiencia de tokens, claridad operativa y capacidad de escalar el sistema sin que el costo se dispare.
Si todavía estás operando con un único agente cargado de skills y prompts genéricos, probablemente estés pagando un overhead mensual que se puede recortar sustancialmente con una arquitectura mejor pensada. Como casi todo en ingeniería: vale la pena la inversión inicial de tiempo, y el ahorro acumulado lo notas turno tras turno.
¿Cómo está estructurada tu arquitectura de agentes hoy? ¿Tu sesión principal lleva el peso de todo, o ya empezaste a delegar responsabilidades?