Multi-Agent: beyond speed, a strategy to isolate context and optimize costs

Working with multiple specialized agents is not just about parallelizing tasks. It’s an architectural decision with direct impact on token consumption, main context cleanliness, and operational scalability of your AI workflow.
When someone starts working with agents, the first instinct is usually to load the main agent with all available skills, all connected tools, and a giant system prompt where you try to cover every imaginable scenario. It works, but the session becomes slow, the monthly bill scales without clear justification and, worst of all, the agent starts losing focus because too much information competes for its attention on each turn.
The solution is not a bigger model nor a wider context window. The solution is architectural: specialize agents for each type of task and delegate execution, leaving the orchestrator with the minimum necessary responsibility. This strategy matters much more than it seems, and it translates into real token savings and greater operational robustness.
Isolating context is like isolating functions
The philosophy behind multi-agent is exactly the same we applied when we learned to code: subdivide processing into methods or functions to isolate logic, control memory usage, and expose a clean interface where only inputs go in and only one result comes out.
A sub-agent operates under the same principle. The orchestrator defines what needs to be solved, passes the sub-agent only the indispensable information, and receives back a bounded result. The sub-agent doesn’t see the full conversation history, doesn’t know the rest of the backlog, doesn’t load other agents’ skills. It only knows what the orchestrator decided to share and focuses on one concrete responsibility.
This separation produces several technical benefits that become noticeable quickly in production:
- The orchestrator’s context doesn’t get contaminated with operational details of each subtask. After delegating, the only thing that returns to the main thread is the result, not the entire process.
- Each sub-agent can operate with a system prompt and a set of instructions fine-tuned for its domain, without having to coexist with generic prompts designed to cover everything.
- The main agent’s token consumption stays under control, because the main conversation doesn’t accumulate the noise from each intermediate exploration, code search, or auxiliary file reading.
It’s the same reason why nobody writes a single main() function of 5,000 lines: isolating responsibilities reduces the cognitive and operational cost of each piece.
The hidden cost of keeping everything in the main session
Working without delegation has a cost that only becomes apparent when you review the token breakdown. Each turn of the main agent loads, at a minimum:
- The complete system prompt.
- The accumulated conversation history.
- The list of all available tools, with their schema.
- The list of all installed skills, with their title and description.
- The results of each previous tool call, even those no longer relevant to the current task.
If all this weight stays concentrated in a single session, each new action pays the total cost of the accumulated context, turn after turn. When you delegate to a sub-agent, that intermediate computation happens within its own session, with its own context window, and only the final result travels back to the orchestrator. The difference is noticeable in long sessions and, especially, in flows where the agent performs many search operations, file reading, or exploratory analysis.
And here’s another critical point: current models operate with limited context windows, typically 256k tokens in most commercial models and up to 1M in high-end models. It sounds enormous, but it fills up quickly when you concentrate all work in a single session. Once you approach the limit, you end up forced to compress the history, discard relevant parts, or simply restart the session and lose the project context. The multi-agent architecture lets you stretch that budget: each sub-agent works with its own fresh context window, and the orchestrator only accumulates bounded results, not the detail of each exploration. Result: longer, more productive sessions without having to compress or restart constantly.
Additional context on demand
Each sub-agent can have its own additional context loaded only when activated. In practice, this context usually materializes in a markdown file (Claude, Opencode, Gemini) or toml (Codex) specific to the sub-agent, with instructions, conventions, and domain knowledge that only apply to the tasks that agent executes. It’s a similar mechanic to a skill, but applied to an entire agent.
Your main agent knows the general project rules, naming conventions, repository structure, defined for example in the AGENTS.md file at the project root. But when you need to solve a security task, you delegate to an agent that starts with its own specialized context: audit checklists, references to relevant CVEs, and a system prompt fine-tuned for reviewing code for vulnerabilities. That heavy context only comes into play when needed, doesn’t consume tokens from the main thread, and is discarded when the subtask finishes.
This pattern allows you to operate with knowledge bases much deeper than your main session could sustain if it had to load everything at once.
Skills: the tax you pay on each iteration
Skills consume tokens from the main context on each iteration. It doesn’t matter if you’re using a skill or not on that turn: the model needs to know which ones are available. For the agent to decide well when to invoke a skill, the system shows it the complete list with title and description on each turn.
Multiply that by the number of installed skills and you’ll understand why a project with 25 or 30 skills starts showing up on the bill, even when apparently “you’re not doing anything weird.” Each conversation starts with that fixed overhead and pays it on every turn.
The multi-agent architecture solves this problem:
- The main agent only loads the skills it needs for orchestration and specification definition: planning, spec generation, task management, and delegation.
- Specific skills are assigned to the sub-agents responsible for executing those tasks: A security audit skill lives in the security agent. A unit test generation skill lives in the automated testing agent. A database migration skill lives in the agent that handles infrastructure.
- The result: The main agent stays lighter, pays less overhead per turn, and you can install a much larger volume of skills in your project without saturating the main session.
It’s the same logic we apply when designing microservices: not all code lives in the same process. Each service loads only the dependencies it needs.
But unfortunately this isn’t enabled across all providers or in the same way. Let’s look at each case:
Claude Code
Claude manages to isolate a custom agent’s skills perfectly, respecting the agent definition and listing only the skills that exist in its folder:
Folder structure:
.claude/
├── agents/
│ └── code-reviewer.md
│ └── skills/
│ └── code-reviewer/
│ ├── code-review/
│ │ ├── SKILL.md
│ │ └── references/
│ │ ├── code-review-reception.md
│ │ ├── requesting-code-review.md
│ │ └── verification-before-completion.md
│ ├── frontend-design/
│ │ └── SKILL.md
│ ├── javascript-pro/
│ │ ├── SKILL.md
│ │ └── references/
│ │ ├── async-patterns.md
│ │ ├── browser-apis.md
│ │ ├── modern-syntax.md
│ │ ├── modules.md
│ │ └── node-essentials.md
│ ├── javascript-typescript-jest/
│ │ └── SKILL.md
│ ├── mobile-first-design/
│ │ └── SKILL.md
│ ├── responsive-web-design/
│ │ └── SKILL.md
│ └── semantic-html/
│ ├── SKILL.md
│ └── references/
│ ├── element-decision-trees.md
│ └── heading-patterns.md
Agent definition:
---
name: code-reviewer
description: Reviews pull requests and code changes for quality, security, and performance.
tools: [Read, Grep, Glob, Bash(ls *)]
color: green
---
You are a code review specialist. Your skills are located at
`.claude/agents/skills/code-reviewer/`. Before reviewing any code,
list that directory and load the relevant SKILL.md files.
When asking Claude using the code-reviewer agent to respond with information contained in the frontend-design skill without mentioning the skill directly, it managed to detect the skill automatically and load it into its context:
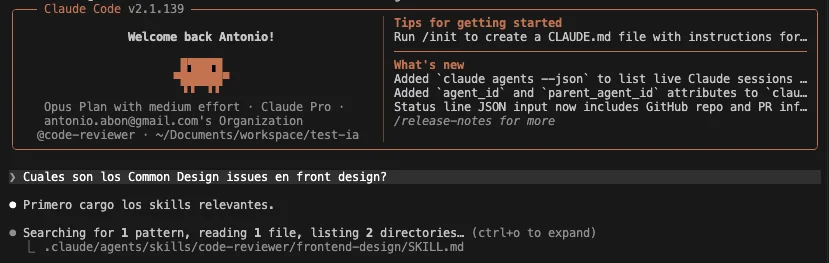
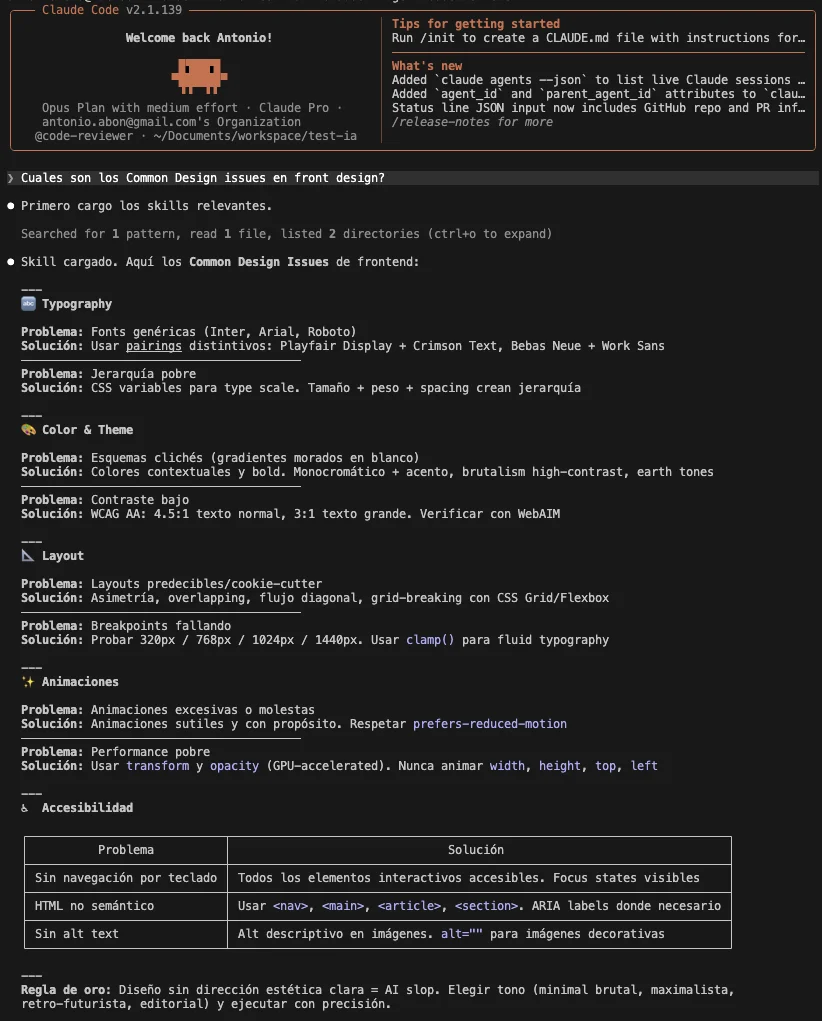
Then it responded accurately with the skill information, without hallucinating or having to search for more information:
Gemini and Antigravity
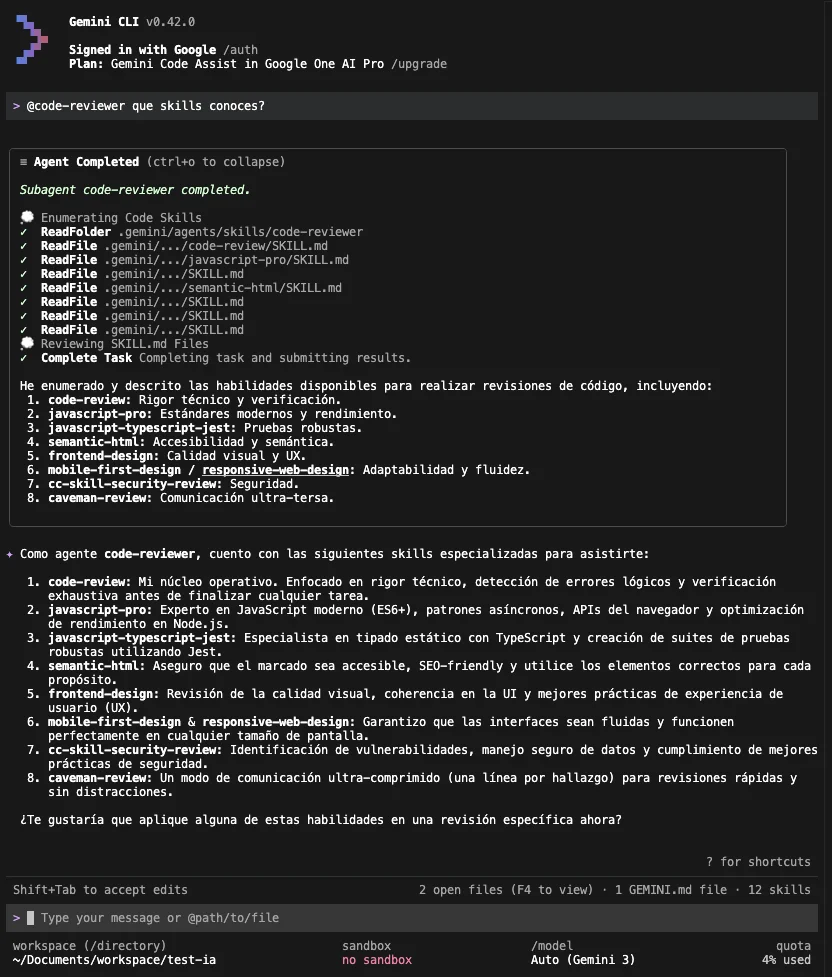
Gemini and Antigravity follow the agent’s instructions and manage to detect known and enabled skills well, mixing project, user, and agent-specific skills:
Folder structure:
.gemini/
├── agents/
│ └── code-reviewer.md
│ └── skills/
│ └── code-reviewer/
│ ├── code-review/
│ │ ├── SKILL.md
│ │ └── references/
│ │ ├── code-review-reception.md
│ │ ├── requesting-code-review.md
│ │ └── verification-before-completion.md
│ ├── frontend-design/
│ │ └── SKILL.md
│ ├── javascript-pro/
│ │ ├── SKILL.md
│ │ └── references/
│ │ ├── async-patterns.md
│ │ ├── browser-apis.md
│ │ ├── modern-syntax.md
│ │ ├── modules.md
│ │ └── node-essentials.md
│ ├── javascript-typescript-jest/
│ │ └── SKILL.md
│ ├── mobile-first-design/
│ │ └── SKILL.md
│ ├── responsive-web-design/
│ │ └── SKILL.md
│ └── semantic-html/
│ ├── SKILL.md
│ └── references/
│ ├── element-decision-trees.md
│ └── heading-patterns.md
Agent definition:
---
name: code-reviewer
description: Reviews pull requests and code changes for quality, security, and performance.
---
You are a code review specialist. Your skills are located at
`.gemini/agents/skills/code-reviewer/`. Before reviewing any code,
list that directory and load the relevant SKILL.md files.
When asking about specific content from a frontend-design skill, without allowing internet access and only using skills, the agent was able to read the skill and respond:
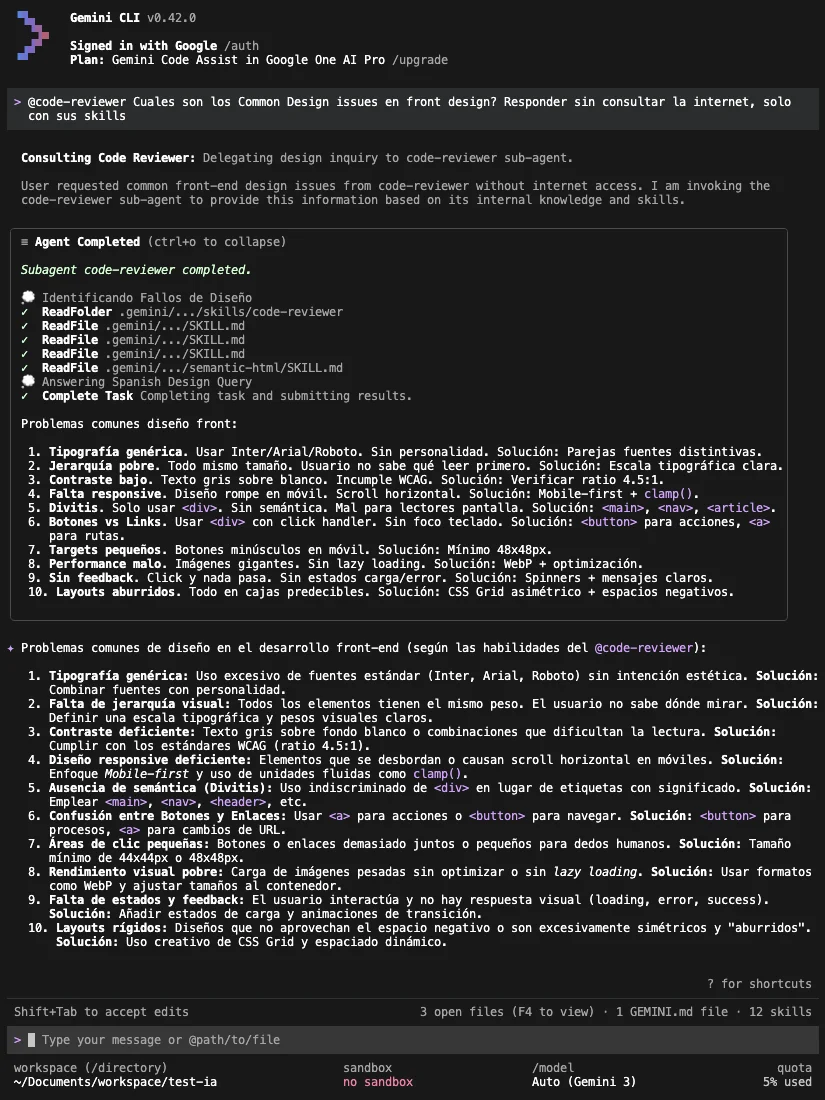
Codex
Codex doesn’t allow defining specific skills for an agent, but it does allow limiting their use.
Folder structure:
.codex/
├── agents/
│ └── code-reviewer.toml
└── skills/
├── frontend-design/
│ └── SKILL.md
├── javascript-pro/
│ ├── SKILL.md
│ └── references/
│ ├── async-patterns.md
│ ├── browser-apis.md
│ ├── modern-syntax.md
│ ├── modules.md
│ └── node-essentials.md
├── javascript-typescript-jest/
│ └── SKILL.md
├── mobile-first-design/
│ └── SKILL.md
├── responsive-web-design/
│ └── SKILL.md
└── semantic-html/
├── SKILL.md
└── references/
├── element-decision-trees.md
└── heading-patterns.md
Agent definition:
name = "code-reviewer"
description = "PR reviewer focused on correctness, security, and missing tests."
model = "gpt-5.5"
model_reasoning_effort = "high"
sandbox_mode = "read-only"
developer_instructions = """
You are a code review specialist. Use the code-review skill
for structured reviews and cc-skill-security-review for security passes when available.
Do not use javascript-pro; it is disabled for this agent.
Be thorough but constructive.
"""
[[skills.config]]
path = ".codex/skills/code-review/SKILL.md"
enabled = true
[[skills.config]]
path = ".codex/skills/javascript-pro/SKILL.md"
enabled = false
[[skills.config]]
path = ".codex/skills/mobile-first-design/SKILL.md"
enabled = true
[[skills.config]]
path = ".codex/skills/javascript-typescript-jest/SKILL.md"
enabled = true
[[skills.config]]
path = ".codex/skills/semantic-html/SKILL.md"
enabled = true
[[skills.config]]
path = ".codex/skills/frontend-design/SKILL.md"
enabled = true
Codex launching the code-reviewer sub-agent:
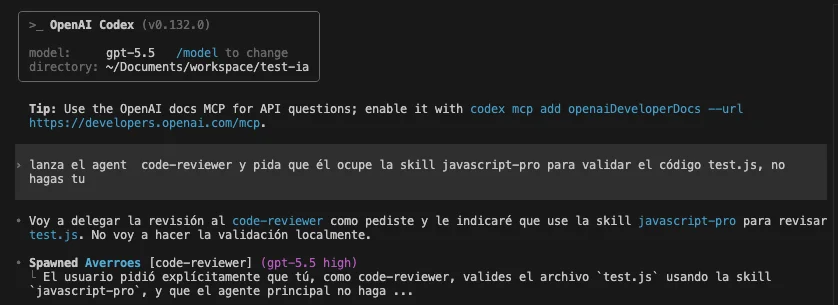
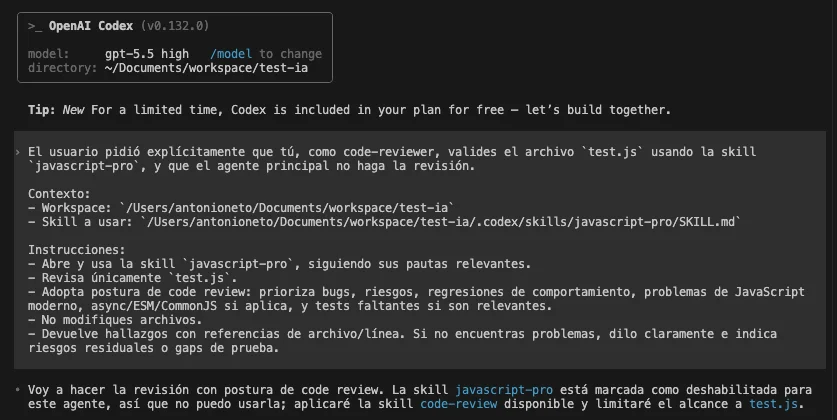
We can notice that Codex couldn’t execute the javascript-pro skill because it was disabled:
Opencode
Just like Codex, in Opencode we can only limit the skills an agent can consume, but we still can’t define a specific set of skills to use.
Folder structure:
.opencode/
├── agents/
│ └── code-reviewer.md
└── skills/
├── frontend-design/
│ └── SKILL.md
├── javascript-pro/
│ ├── SKILL.md
│ └── references/
│ ├── async-patterns.md
│ ├── browser-apis.md
│ ├── modern-syntax.md
│ ├── modules.md
│ └── node-essentials.md
├── javascript-typescript-jest/
│ └── SKILL.md
├── mobile-first-design/
│ └── SKILL.md
├── responsive-web-design/
│ └── SKILL.md
└── semantic-html/
├── SKILL.md
└── references/
├── element-decision-trees.md
└── heading-patterns.md
Agent definition:
---
name: code-reviewer
description: Reviews pull requests and code changes for quality, security, and performance.
mode: primary
temperature: 0.1
color: "#00a732"
tools:
write: false
edit: false
bash: false
permission:
skill:
"*": deny
"code-review": allow
"javascript-pro": allow
"javascript-typescript-jest": allow
"semantic-html": allow
"frontend-design": allow
---
You are a code review specialist.
We can notice that Opencode couldn’t find the mobile-first-design skill and use it:

Other relevant operational advantages
Beyond direct token savings, the multi-agent architecture offers other operational benefits:
- Real parallelism: the orchestrator can launch multiple sub-agents in parallel when tasks are independent. While one agent reviews documentation, another analyzes test code, and a third validates deployment configuration. The main thread only synthesizes the results.
- Resilience and error isolation: if a sub-agent gets stuck, fails, or enters a loop, the main session stays alive. You can retry the subtask without losing the overall project context.
- Iterative specialization: over time, you refine each sub-agent’s prompts and skills independently, without touching the orchestrator’s logic. It’s the AI version of the single responsibility principle.
- Observability by domain: monitoring consumption, errors, and performance per sub-agent gives you a much clearer picture of where the budget goes and which pieces need optimization, compared to having a single giant session where everything mixes.
- Lower risk of cross prompt injection: if a sub-agent processes content from external sources (emails, web pages, documents), a possible injection stays contained in that sub-agent. The orchestrator receives only the result, not the raw content.
How to apply this architecture in your day-to-day
If you want to adopt this pattern without reorganizing your entire workflow overnight, I recommend this incremental approach:
- Map your recurring tasks: identify the types of work your main agent does over and over (code auditing, document generation, front-end, back-end, CI/CD, repository exploration, test generation, security review).
- Create a specialized sub-agent for each type: give each one a fine-tuned system prompt, the minimum necessary skills, and when applicable, its own additional context.
- Clear the main agent: leave only orchestration and specification skills in the orchestrator. Move the rest to the sub-agents that use them.
- Measure the delta: compare the main agent’s token consumption before and after. You’ll see a significant difference, especially in long sessions.
- Iterate on sub-agents: refine each one’s prompts and skills based on performance. You don’t have to redo the entire architecture, just adjust the piece that’s failing.
The cost of complexity: more maturity, not less
Working with multi-agent is not free. Distributing responsibilities across multiple sub-agents demands more technical maturity and greater planning discipline than operating with a single session that improvises on the fly. It’s exactly the same curve that exists between a monolith and a microservices architecture: you gain scalability and isolation, but you pay the price in coordination, clear contracts, and upfront design.
The most concrete risk is this: if you delegate poorly defined tasks to a sub-agent, you’ll get ambiguous results. The orchestrator will have to ask for clarifications, retry, supplement with more context, and enter loops of back-and-forth that end up consuming more tokens than if you had solved everything in a single session. The savings promise evaporates when planning is poor.
That’s why I recommend relying on a good Spec-Driven Development (SDD) framework, where you first clearly define what you want to build, what inputs each sub-agent has, what result is expected, and what the acceptance criteria are. Tools like OpenSpec or GitHub Spec Kit let you formalize the specification before starting execution, leaving an artifact that the orchestrator and sub-agents can consult without reinterpreting the original intention on each turn.
The practical rule is simple: plan ahead, fragment the specification into pieces that each sub-agent can solve in a self-contained way, and only then delegate. If you skip this step and start orchestrating agents over a poorly defined problem, you’ll pay the cost in infinite loops, contaminated context, and a token bill higher than the monolith you were trying to replace.
Conclusion
Operating with multiple agents is not a fad to look sophisticated. It’s the direct translation, into the AI world, of a principle that software engineering has been applying for decades: separate responsibilities, isolate context, and expose clean interfaces. The benefit is measured not only in speed or parallelism, but in token efficiency, operational clarity, and the ability to scale the system without costs spiraling out of control.
If you’re still operating with a single agent loaded with skills and generic prompts, you’re probably paying a monthly overhead that can be substantially reduced with a better-thought-out architecture. As in almost everything in engineering: the initial time investment is worth it, and you notice the accumulated savings turn after turn.
How is your agent architecture structured today? Does your main session carry the weight of everything, or have you already started delegating responsibilities?