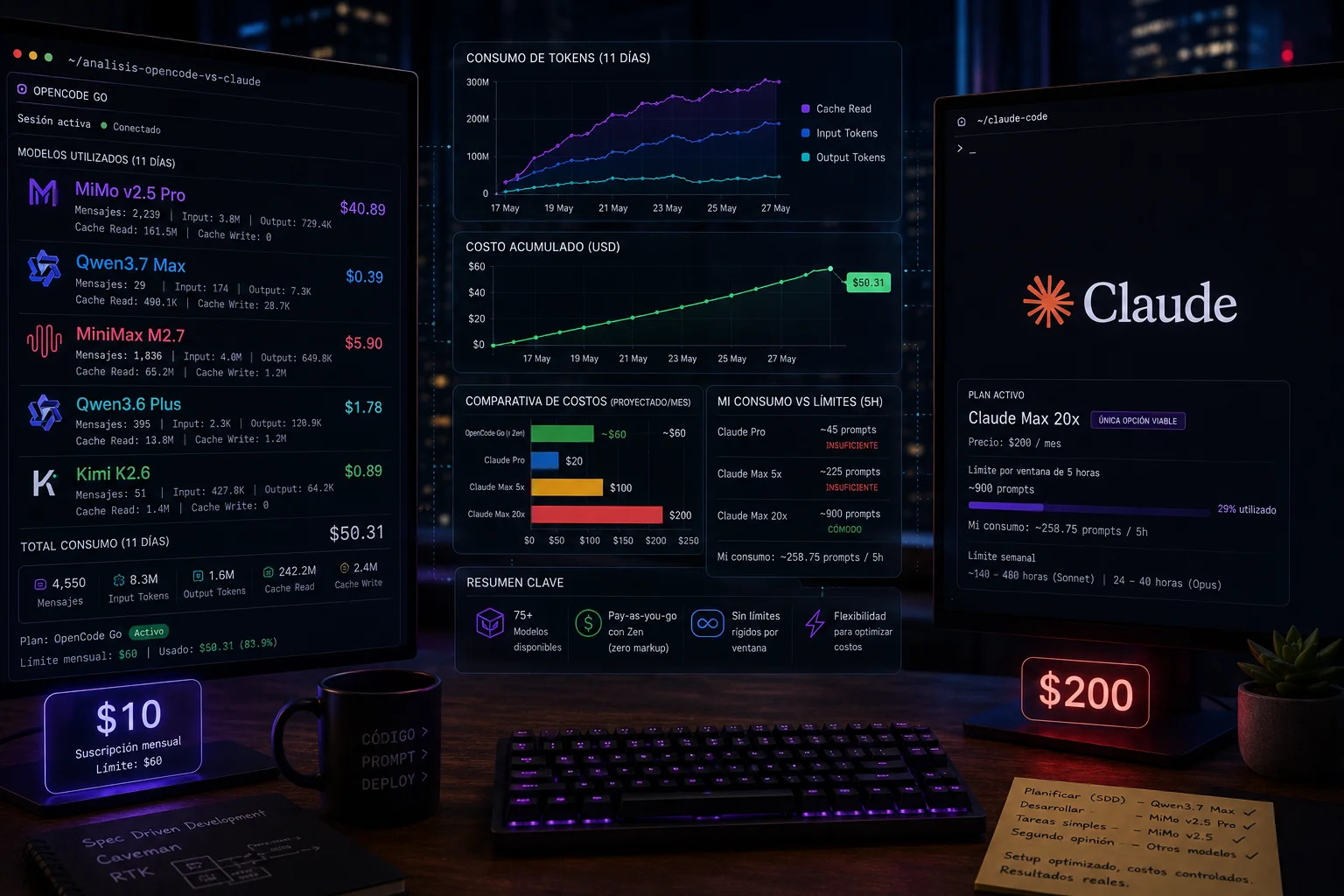
>_ Opencode Go vs Claude Code: Un análisis real de 11 días
$60 en consumo de API por $10 de suscripción. Un análisis real de 11 días comparando Opencode Go vs Claude Code: costos, límites y cuándo tiene sentido cambiar.
// recent_posts — últimos publicados
ls -la archivo →
Desmitificando el AI First: la prioridad estratégica
AI First no es meter IA en todo ni una estrategia aislada. Es una prioridad estratégica que convive con Data First, Security First y Cloud First. El rol del arquitecto: que las prioridades fuera del top 5 no se pierdan.

Multi-Agente: más allá de la velocidad, una estrategia para aislar contexto y optimizar costos
Cuando alguien empieza a operar con agentes, el primer instinto suele ser cargar al main agent con todas las skills disponibles, todas las herramientas conectadas y un system prompt gigante donde se...

HITL en Vibe Coding e IaC: evita la factura larga
En 2026 el discurso corporativo va casi todo en una sola dirección: agentes autónomos, full automation, self-healing pipelines. La promesa es seductora porque vende. La realidad operativa es que casi...

Fine-tuning vs. RAG: cuándo cada uno tiene ROI real en producción
Ya vimos cómo bajar el costo de inferencia usando modelos open-weight como Qwen 3.5 en el artículo Reduciendo el costo en producción: Qwen 3.5 en AWS vs APIs Comerciales. Pero cuando tienes el costo...

LLM-as-a-Judge: cómo construir pipelines de evaluación de IA que escalen
Los prompts en sistemas con Large Language Models (LLMs) no se comportan como código determinista. En un desarrollo de software tradicional, si modificas una función y todos los tests pasan, puedes...

Auditoría de Skills: Protegiendo tu Infraestructura de los Sleeping Payloads
Las skills y los agentes son probablemente lo mejor que le ha pasado al ecosistema de IA en los últimos años. Una skill es, en esencia, una abstracción potente: encapsula conocimiento y scripts...

Reduciendo el costo en producción: Qwen 3.5 en AWS vs OpenAi
Análisis técnico: AWS SageMaker vs OpenAi. Descubre por qué alojar modelos open-weights es vital para rentabilidad y latencia.

Antonio Barbosa
Ingeniero de Software con más de 19 años de experiencia liderando el diseño, desarrollo y escalamiento de sistemas en empresas como Buk, Walmart Chile, Cencosud y Globant. Mi trabajo cubre el ciclo completo: arquitectura backend, cloud, DevOps, frontend y, recientemente, integración de Large Language Models (LLMs) y funcionalidades agentic AI en producción.