Reduciendo el costo en producción: Qwen 3.5 en AWS vs OpenAi
Análisis técnico: AWS SageMaker vs OpenAi. Descubre por qué alojar modelos open-weights es vital para rentabilidad y latencia.

Las APIs gestionadas de proveedores LLM son el estándar de la industria hoy en día. Sin embargo, cuando una aplicación pasa de la fase de prototipo a producción y debe soportar usuarios concurrentes de verdad, el modelo de cobrar por token se vuelve rápidamente un problema financiero.
Para quienes diseñamos arquitecturas a escala, pasarnos a modelos open-weights en infraestructura propia va más allá de un tema de privacidad de datos. Como exploré recientemente en mi análisis sobre cómo reducir hasta un 90% los costos de LLMs, se trata de una decisión puramente de viabilidad económica y control de la latencia.
Este artículo desglosa los números exactos de costos y rendimiento al comparar el despliegue de la familia de modelos Qwen 3.5 (9B, 35B y 122B) en AWS SageMaker Real-time Inference contra las versiones comerciales de OpenAI.
El Glosario de Inferencia
Antes de ver los números, repasemos las métricas que definen el rendimiento de un modelo en producción:
- AWS SageMaker Real-time Inference: El entorno que usaremos para levantar los endpoints dedicados. Permite desplegar contenedores optimizados manteniendo el control del hardware.
- TPS (Tokens Per Second): El throughput puro del hardware. Cuántos tokens procesa la GPU por segundo.
- TTFT (Time To First Token): El tiempo desde que el usuario envía el prompt hasta que el servidor devuelve la primera palabra. Define qué tan rápido se siente el sistema.
- TPOT (Time Per Output Token): La velocidad a la que se genera el texto. El ojo humano lee a unos 5–8 tokens por segundo; nuestro sistema tiene que ser más rápido que eso.
- Continuous Batching: La técnica de los motores modernos (como vLLM o TGI) que permite procesar varias peticiones concurrentes, solapando la lectura del contexto de un usuario con la generación de palabras de otro para aprovechar la VRAM al máximo.
Análisis de Build vs. Buy
El Escenario Base
Para sacar estos cálculos, modelamos el siguiente entorno de alta demanda:
- Carga de trabajo: 32 usuarios concurrentes exigiendo al servidor 24/7.
- Tiempo operativo: 1 mes completo (2.628.000 segundos o 730 horas).
- Tráfico por ciclo analizado: 3.000 millones de tokens de Input (lectura) y 500 millones de tokens de Output (generación).
1. Categoría 9B: Qwen 3.5 vs GPT-4.1
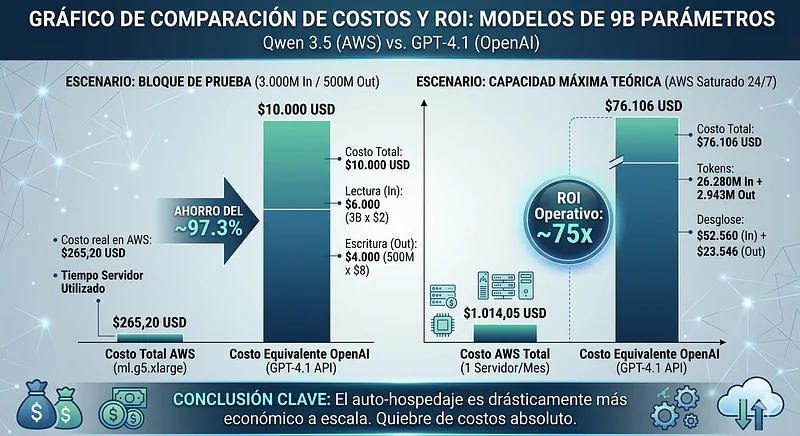
Para modelos de 9 billones de parámetros (qwen3.5 9B Non-reasoning), las instancias base de la serie G de AWS son suficientes. Comparamos los costos asumiendo las tarifas de GPT-4.1 ($2 USD por 1M Input / $8 USD por 1M Output).
Costo Mensual de Hardware (AWS):
ml.g6.xlarge: $811,22 USD (Costo por segundo: $0,000309)ml.g5.xlarge: $1.014,05 USD (Costo por segundo: $0,000386)
El Costo del Bloque de Prueba (3.000M In / 500M Out): Si ejecutamos nuestra carga base en la infraestructura propia, calculamos la fracción de tiempo de servidor utilizada y su costo equivalente. En OpenAI, este mismo bloque costaría $10.000 USD ($6.000 de lectura + $4.000 de escritura). Veamos cuánto cuesta procesar exactamente ese mismo volumen en nuestro hardware dedicado calculando la fracción de tiempo utilizada:
En ml.g6.xlarge:
- Input (10.000 TPS) = $92,7 USD en tiempo de máquina
- Output (900 TPS) = $171,5 USD en tiempo de máquina
- Costo real en AWS = $264,2 USD
En ml.g5.xlarge:
- Input (10.000 TPS) = $115,8 USD
- Output (1.120 TPS) = $172,5 USD
- Costo real en AWS = $265,2 USD
Gastar ~$265 dólares de tiempo de máquina frente a $10.000 dólares de API demuestra un quiebre absoluto en la curva de costos.
Capacidad Máxima Teórica (Servidor al 100% 24/7): Llevando el hardware al límite durante todo el mes, el valor de los tokens procesados frente a las tarifas de OpenAI es abrumador. Si saturamos la ml.g5.xlarge, la matemática de producción es la siguiente:
- Input Máximo: 26.280 Millones de tokens.
- Output Máximo: 2.943 Millones de tokens.
- Costo en AWS: ~1.014,05 USD (1 servidor mensual)
- Costo Equivalente en GPT-4.1: $76.106 USD ($52.560 In + $23.546 Out).
- Retorno Operativo (ROI): ~75x
2. Categoría 35B: Qwen 3.5 vs GPT-5.2
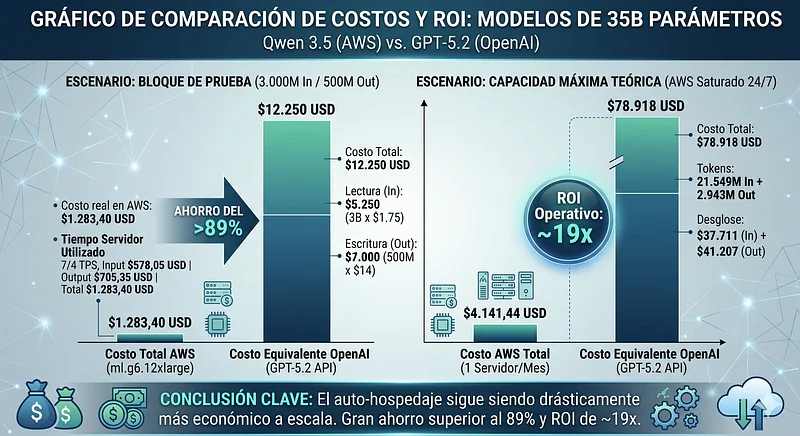
Dar el salto a 35B (qwen3.5 35B Non-reasoning) mejora el razonamiento lógico, pero requiere mayor VRAM y memoria unificada. Comparamos frente a GPT-5.2 ($1,75 USD Input / $14 USD Output).
Costo Mensual de Hardware (AWS):
ml.g6.12xlarge: $4.141,44 USD (Costo por segundo: $0,00158)
El Costo del Bloque de Prueba (3.000M In / 500M Out): En OpenAI, facturar este volumen costaría $12.250 USD ($5.250 de lectura + $7.000 de escritura). Veamos cuánto cuesta procesar exactamente ese mismo volumen en nuestra infraestructura:
| En ml.g6.12xlarge (Input 8.200 TPS | Output 1.120 TPS): |
- Input: $578,05 USD en tiempo de máquina
- Output: $705,35 USD en tiempo de máquina
- Costo real en AWS = $1.283,40 USD
Gastar ~$1.285 dólares de tiempo de máquina frente a $12.250 dólares de API sigue demostrando un ahorro masivo superior al 89%.
Capacidad Máxima Teórica (Servidor al 100% 24/7): La instancia g6.12xlarge, impulsada por arquitectura Ada Lovelace, lee tokens sustancialmente más rápido, elevando el techo de procesamiento. Al saturarla durante un mes, esta es su capacidad máxima operativa:
- Input Máximo: 21.549 Millones de tokens.
- Output Máximo: 2.943 Millones de tokens.
- Costo en AWS: ~4.141,44 USD (1 servidor mensual)
- Costo Equivalente en GPT-5.2: $78.918 USD ($37.711 In + $41.207 Out).
- Retorno Operativo (ROI): ~19x
3. Categoría Heavyweight (122B): Arquitectura L40S vs GPT-5.4
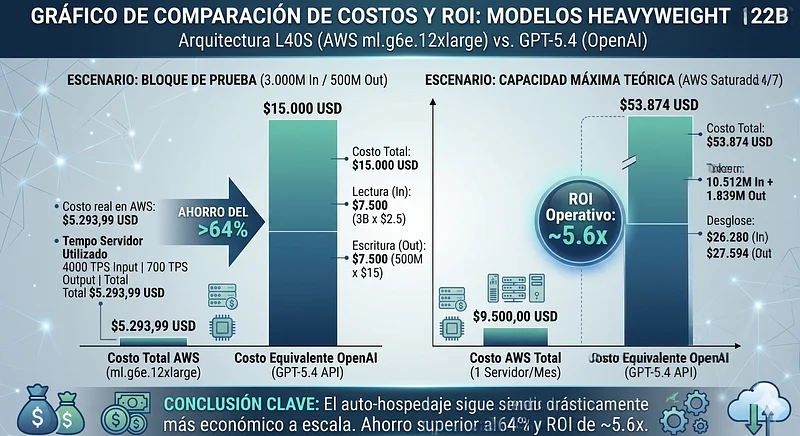
Para desplegar un modelo de clase 120B+ (qwen3.5 122B Non-reasoning) cuantizado en 4-bit (AWQ), el peso del modelo ronda los 81GB de VRAM. Sumando la memoria necesaria para el KV Cache de 32 usuarios concurrentes, las máquinas anteriores colapsarían por Out Of Memory (OOM).
La solución arquitectónica óptima es la instancia ml.g6e.12xlarge, que proporciona 4 GPUs NVIDIA L40S, sumando 192GB de VRAM total con un ancho de banda masivo de 864 GB/s por tarjeta. Comparamos contra tarifas de GPT-5.4 ($2,5 USD Input / $15 USD Output).
Costo Mensual de Hardware (AWS):
ml.g6e.12xlarge: $9.500,00 USD (Costo por segundo: $0,00361)
El Costo del Bloque de Prueba (3.000M In / 500M Out): En OpenAI (GPT-5.4), este volumen exige exactamente $15.000 USD ($7.500 de lectura + $7.500 de escritura). Veamos la comparativa en nuestro servidor dedicado:
-
En ml.g6e.12xlarge (Input 4.000 TPS Output 700 TPS): - Input: $2.711,99 USD en tiempo de máquina
- Output: $2.582,00 USD en tiempo de máquina
- Costo real en AWS = $5.293,99 USD
Aún en la categoría más pesada de modelos comerciales, la infraestructura propia es casi un 65% más barata para este lote específico.
Capacidad Máxima Teórica (Servidor al 100% 24/7): Al saturar esta máquina 24/7, obtenemos un ROI multiplicador de 5.6x. Pagamos $9.500 por hardware dedicado para obtener casi $54K de valor en facturación de API:
- Input Máximo: 10.512 Millones de tokens.
- Output Máximo: 1.839 Millones de tokens.
- Costo Equivalente en GPT-5.4: $53.874 USD ($26.280 In + $27.594 Out).
- Retorno Operativo (ROI): ~5.6x
Escalamiento y Concurrencia
Hay que tener en cuenta que estos números asumen un solo servidor respondiéndole a 32 usuarios al mismo tiempo para mantener la latencia lo más baja posible. En la vida real, esto es mucho más flexible.
El servidor aguanta más usuarios concurrentes si aceptamos bajar un poco los Tokens Per Second (TPS) por usuario, siempre y cuando no bajemos de la velocidad de lectura humana (TPOT).
Además, al usar AWS SageMaker no dependemos de un solo nodo. Configuramos políticas de Auto-Scaling para levantar más instancias automáticamente si hay picos de tráfico, y apagarlas cuando no hay usuarios. Esto nos permite escalar bajo demanda sin inflar demasiado los costos. Sin embargo, hay que considerar que el tiempo de escalado del nodo nuevo tarda entre 5 y 15 min en quedar listo (pull del container, descarga de pesos del LLM, carga en VRAM, etc.).
La Velocidad y la Experiencia de Usuario (UX)
Los números hablan por sí solos, pero administrar tus propios servidores también mejora la experiencia del usuario. Las APIs comerciales de OpenAI son entornos multi-tenant; tu tráfico compite en colas públicas y pasa por rate-limits, lo que mete picos de latencia que no puedes controlar.
Al tener tus propios endpoints en SageMaker:
- TTFT Instantáneo: Como no hay colas globales, el tiempo hasta que aparece la primera palabra baja a milisegundos. La app se siente rápida.
- TPOT Constante: GPUs como la L40S escupen texto mucho más rápido de lo que un usuario puede leer.
- Latencia de Red: Tener la inferencia en la misma región de AWS que tu base de datos y tu backend te quita de encima los retrasos de red de estar haciendo peticiones a internet público.
Los modelos de OpenAI en output:
- GPT-4.1: 37 TPS
- GPT-5.2: 46 TPS
- GPT-5.4: 43 TPS
El modelo qwen3.5 en AWS con 32 usuarios concurrentes en 2 servidores:
- 9B: 70 TPS (35 x 2)
- 35B: 70 TPS (35 x 2)
- 122B: 43,74 TPS (21,87 x 2)
Con 16 usuarios concurrentes:
- 9B: 140 TPS (70 x 2)
- 35B: 140 TPS (70 x 2)
- 122B: 87,48 TPS (43,74 x 2)
Con 8 usuarios concurrentes:
- 9B: 280 TPS (140 x 2)
- 35B: 280 TPS (140 x 2)
- 122B: 174,96 TPS (87,48 x 2)
Como podemos ver, la capacidad de los servidores es finita y la capacidad de TPS en output va a depender de la cantidad de solicitudes simultáneas que el servidor puede estar experimentando al instante de responder la solicitud.
Maximizando la inversión en hardware
Un detalle técnico que suele pasar desapercibido al rentar instancias de gran tamaño (como la ml.g6e.12xlarge con sus 4 GPUs y 192GB de VRAM total) es que no estás obligado a dedicar todo ese hardware a un solo modelo monolítico.
Si tu arquitectura lo requiere, puedes consolidar cargas de trabajo para exprimir la inversión al máximo. Por ejemplo, si el modelo de 122B cuantizado ocupa unos 81GB de VRAM, te queda más de la mitad de la memoria libre. Ese espacio sobrante te permite correr modelos adicionales en la misma máquina sin pagar un dólar extra.
Podrías tener el modelo heavyweight (122B) atendiendo tareas de razonamiento complejo, y corriendo al lado, en el mismo servidor, un par de modelos más pequeños y rápidos (como versiones de 9B) dedicados exclusivamente a tareas de clasificación, extracción de datos o routing.
Incluso si usas técnicas como LoRA (Low-Rank Adaptation), motores como vLLM te permiten cargar un solo modelo base en la memoria y aplicarle múltiples adaptadores sobre la marcha para diferentes casos de uso. Básicamente, dejas de pagar por “el modelo” y pasas a ser dueño de una “capacidad de cómputo” bruta, exprimiendo cada gigabyte de memoria y multiplicando aún más el ROI frente a las APIs comerciales.
Costos Reales y Red
El análisis matemático anterior se centra en el gasto principal y más pesado: el cómputo puro (precio por hora de la instancia). Sin embargo, en un despliegue de producción real, la factura final tendrá una variación marginal debido a costos periféricos propios del ecosistema de nube.
Al levantar endpoints en SageMaker, debes contemplar cargos adicionales menores. Estos incluyen el almacenamiento EBS necesario para alojar los pesos del modelo y los contenedores, así como posibles cargos por Data Transfer In dependiendo de cómo inyectes la información al sistema.
Pero aquí es donde el diseño de la arquitectura juega a tu favor: el temido Data Transfer Out, que suele ser el costo oculto más agresivo y destructivo en la nube, queda neutralizado. Si tu backend o microservicios consultan el modelo operando estrictamente dentro de la misma VPC (Virtual Private Cloud), la transferencia de salida de esos millones de tokens generados es gratuita.
Todo el volumen pesado de texto transita de forma segura por la red interna de AWS. Esto asegura que los costos periféricos se mantengan en un porcentaje mínimo y no alteren el abrumador ROI que ofrece el hardware dedicado frente a las APIs públicas.
Savings Plans
Es posible economizar hasta 43% sin pagar ninguno USD por adelantado con Savings Plans, para esto solo debemos elegir la duración de 3 años, sin gastos iniciales, definir el monto de USD por hora que gustaría ahorrar y todo gasto adicional se cobrará con el precio bajo demanda. Por ejemplo, si sabemos que vamos a ocupar mínimamente por 3 años modelos 9B o superior, podemos definir un ahorro por hora de 1522 USD (precio de 2 instancias ml.g5.xlarge mensuales).
Ejemplos de uso con 3 años:
ml.g5.xlargemansual normal $1.014 USD (Costo por segundo: $0,000386), con saving plans $547,92 USD (Costo por segundo: $0,0002084)ml.g6.12xlargemansual normal $4.141,44 USD (Costo por segundo: $0,00158), con saving plans $23767,15 USD (Costo por segundo: $0,009043)ml.g6e.12xlargemansual normal $9.500,00 USD (Costo por segundo: $0,00361), con saving plans $4895,44 USD (Costo por segundo: $0,00186)
Resiliencia
Minimamente para un ambiente productivo real, debemos mantener dos instancias en dos AZs (zonas de disponibilidad) para mantener la alta disponibilidad del servicio. Esto representa un costo doble de servidor, pero garantiza el doble de TPS, lo que garantiza el ROI descrito anteriormente, una vez que tendremos más capacidad de interpretación y generación de tokens.
Opción Serveless con Amazon Bedrock
Amazon Bedrock proporciona acceso a modelos open-weight de código abierto a través de una API unificada, de forma completamente gestionada y serverless, sin necesidad de gestionar infraestructura.
La familia Qwen ya está disponible en esta plataforma: los cuatro modelos Qwen3 disponibles incluyen Qwen3-Coder-480B-A35B-Instruct, Qwen3-Coder-30B-A3B-Instruct, Qwen3–235B-A22B-Instruct-2507 y Qwen3–32B Dense, con arquitecturas tanto de Mixture-of-Experts (MoE) como densa.
La propuesta de Bedrock es simple: pagas exclusivamente por los tokens que consumes, sin comprometerte con un servidor dedicado. Amazon Bedrock utiliza un modelo de precios basado en tokens, pagando por millón de tokens procesados, donde los tokens de entrada siempre son más baratos que los de salida, típicamente entre 3 y 5 veces más baratos. A modo de referencia, el modelo Qwen3-Coder-480B en Bedrock tiene un precio de $1,50 por millón de tokens de entrada y $7,50 por millón de tokens de salida.
Que significa esto, si no quieres pagar por servidores fijos o por hora, aún así podría ocupar modelos open-weight con Amazon Bedrock con precios mucho más bajos que proveedores tradicionales como OpenAi.
Comparación
- Input: 21.549 Millones de tokens.
- Output: 2.943 Millones de tokens.
- Qwen3 235B A22B 2507 con Amazon Bedrock: $7.331,069 USD ($4.740,912 In + $2.590,157 Out)
- qwen3.5 35B en SageMaker: ~8.282,88 USD (2 servidores mensuales)
- qwen3.5 9B en SageMaker: ~2.028,1 USD (2 servidores mensuales)
- Costo Equivalente en GPT-5.2: $78.918 USD ($37.711 In + $41.207 Out).
Como podemos ver Qwen3 235B A22B 2507 con Amazon Bedrock puede ser más barato que incluso Qwen3.5 35B en SageMaker, sin embargo el modelo es inferior en inteligencia y velocidad. Como podemos ver en esta comparativa, hasta mismo el modelo de 9B de Qwen3.5 en SageMaker es más inteligente, rápido y barato que Bedrock. Esto demuestra que las generaciones de modelos pesan más que el tamaño de los parámetros al determinar la inteligencia y la capacidad de los modelos en la ejecución de las tareas.
Cuándo Tiene Sentido Bedrock
Bedrock no compite directamente con un despliegue propio en SageMaker; en realidad, encaja en una etapa muy específica del ciclo de vida del producto.
Si durante tus pruebas alguno modelo de Amazon Bedrock te atende perfectamente en inteligencia y tiempos de respuestas, acredito que sería una mejor opción que servidores dedicados de SageMaker, principalmente porque Bedrock es Ideal para:
- Fases de validación extendida. Cuando ya superaste el prototipo pero aún no tienes certeza sobre el volumen de producción. Pagas solo por lo que usas, sin comprometerte con un servidor que puede quedar ocioso.
- Tráfico muy irregular o bajo. Si tu aplicación tiene picos esporádicos separados por horas de inactividad, pagar por un servidor dedicado 24/7 destruye el ROI. Bedrock factura al milisegundo de uso real.
- Equipos pequeños sin DevOps dedicado. Bedrock elimina la complejidad de la gestión de infraestructura con acceso serverless y pago por consumo. No hay contenedores que mantener, no hay actualizaciones de drivers de CUDA, no hay alertas de errores a las 3 AM.
- Múltiples modelos en experimentación. Con Bedrock no solo puedes usar modelos propietarios de Amazon, sino también modelos open-source como Qwen, Llama o Mistral cambiando únicamente el campo del modelo en tu código, sin despliegues de endpoints adicionales.
Conclusión
A nivel de arquitectura, el ciclo de vida de un producto con IA es bastante predecible. La elección entre OpenAI, Amazon Bedrock y SageMaker es una progresión natural dictada por el volumen y la madurez de tu producto. Proveedores como OpenAI es el punto de entrada ideal: sin fricción, sin infraestructura, perfecto para validar la idea. Bedrock ocupa el escalón intermedio: te mantiene en el ecosistema AWS con modelos open-weight como Qwen, elimina el riesgo del costo fijo y te da flexibilidad para crecer sin compromisos, aunque sigues pagando por token y compartiendo infraestructura con otros clientes. SageMaker es la etapa final: cuando el volumen es predecible y constante, el costo fijo se convierte en tu mayor ventaja competitiva, dándote control absoluto sobre la latencia, el hardware y los márgenes. La señal para migrar de una etapa a la siguiente es siempre la misma: cuando el modelo de cobro actual empieza a castigar tu crecimiento, es momento de subir un nivel.
Sin embargo, si a tu aplicación le va bien, depender de un proveedor externo trae dos problemas críticos. Primero, el modelo de pago por token castiga tu crecimiento: a más usuarios, menores márgenes. Segundo, delegas por completo la experiencia de tus usuarios a una cola pública; si la API de terceros se satura, tu aplicación se vuelve lenta e inestable, y no puedes hacer nada al respecto.
Desplegar modelos open-weight robustos (como Qwen 3.5) en AWS soluciona ambas partes de la ecuación. En lo financiero, pasas de un gasto variable a un costo mensual fijo y predecible, logrando ahorros de hasta un 98%. En lo técnico, al ser dueño del hardware eliminas los picos de latencia, reduces el tiempo de respuesta a milisegundos y garantizas una interacción fluida en todo momento.
En resumen: cuando llegas a la etapa de producción seria, levantar tu propia infraestructura deja de ser un simple experimento para ahorrar dinero. Se convierte en la única forma de garantizar que tu negocio sea rentable y que tus usuarios tengan un producto rápido, privado y confiable sin importar cuánto escales.
Lee también mi post reciente sobre este tema: Reduciendo hasta un 90% los costos de LLMs con modelos open-weights