Reducing Production Costs: Qwen 3.5 on AWS vs OpenAI
Technical analysis: AWS SageMaker vs OpenAI. Discover why hosting open-weight models is critical for profitability and latency.

Managed APIs from LLM providers are the industry standard today. However, when an application moves from prototype to production and must support real concurrent users, the pay-per-token model quickly becomes a financial problem.
For those of us who design architectures at scale, switching to open-weight models on our own infrastructure goes beyond data privacy. As I recently explored in my analysis on how to reduce LLM costs by up to 90%, it’s a purely economic viability and latency control decision.
This article breaks down the exact cost and performance numbers when comparing the deployment of the Qwen 3.5 model family (9B, 35B, and 122B) on AWS SageMaker Real-time Inference against OpenAI’s commercial versions.
The Inference Glossary
Before looking at the numbers, let’s review the metrics that define model performance in production:
- AWS SageMaker Real-time Inference: The environment we’ll use to spin up dedicated endpoints. It allows deploying optimized containers while maintaining hardware control.
- TPS (Tokens Per Second): The raw throughput of the hardware. How many tokens the GPU processes per second.
- TTFT (Time To First Token): The time from when the user sends the prompt until the server returns the first word. It defines how fast the system feels.
- TPOT (Time Per Output Token): The speed at which text is generated. The human eye reads at about 5–8 tokens per second; our system needs to be faster than that.
- Continuous Batching: The technique used by modern engines (like vLLM or TGI) that allows processing multiple concurrent requests, overlapping context reading from one user with word generation from another to maximize VRAM usage.
Build vs. Buy Analysis
The Baseline Scenario
To derive these calculations, we modeled the following high-demand environment:
- Workload: 32 concurrent users demanding from the server 24/7.
- Uptime: 1 full month (2,628,000 seconds or 730 hours).
- Traffic per analyzed cycle: 3 billion Input tokens (reading) and 500 million Output tokens (generation).
1. 9B Category: Qwen 3.5 vs GPT-4.1
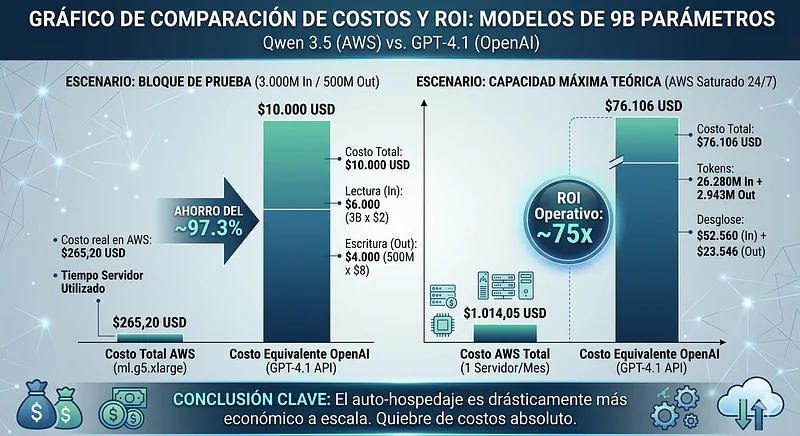
For 9 billion parameter models (qwen3.5 9B Non-reasoning), AWS G-series base instances are sufficient. We compare costs assuming GPT-4.1 rates ($2 USD per 1M Input / $8 USD per 1M Output).
Monthly Hardware Cost (AWS):
ml.g6.xlarge: $811.22 USD (Cost per second: $0.000309)ml.g5.xlarge: $1,014.05 USD (Cost per second: $0.000386)
The Test Block Cost (3B In / 500M Out): If we run our base load on our own infrastructure, we calculate the fraction of server time used and its equivalent cost. On OpenAI, this same block would cost $10,000 USD ($6,000 for reading + $4,000 for writing). Let’s see how much it costs to process exactly that same volume on our dedicated hardware by calculating the fraction of time used:
On ml.g6.xlarge:
- Input (10,000 TPS) = $92.7 USD in machine time
- Output (900 TPS) = $171.5 USD in machine time
- Actual AWS cost = $264.2 USD
On ml.g5.xlarge:
- Input (10,000 TPS) = $115.8 USD
- Output (1,120 TPS) = $172.5 USD
- Actual AWS cost = $265.2 USD
Spending ~$265 in machine time versus $10,000 in API costs demonstrates an absolute break in the cost curve.
Maximum Theoretical Capacity (Server at 100% 24/7): Pushing the hardware to the limit for the entire month, the value of tokens processed versus OpenAI rates is overwhelming. If we saturate the ml.g5.xlarge, the production math is as follows:
- Maximum Input: 26,280 million tokens.
- Maximum Output: 2,943 million tokens.
- AWS Cost: ~$1,014.05 USD (1 monthly server)
- Equivalent GPT-4.1 Cost: $76,106 USD ($52,560 In + $23,546 Out).
- Operational ROI: ~75x
2. 35B Category: Qwen 3.5 vs GPT-5.2
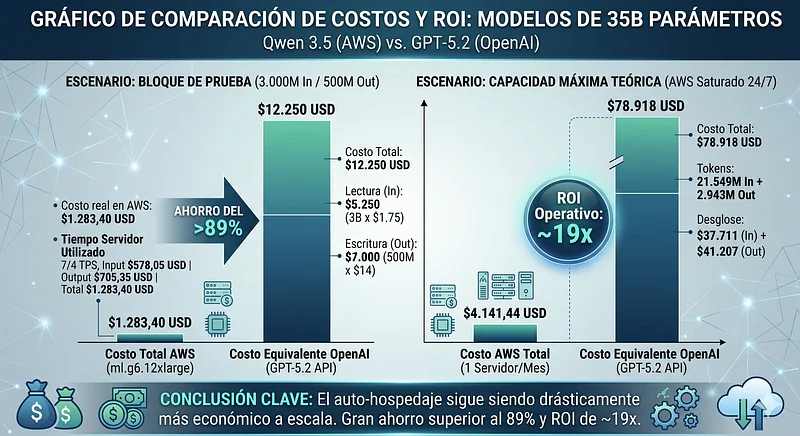
Jumping to 35B (qwen3.5 35B Non-reasoning) improves logical reasoning but requires more VRAM and unified memory. We compare against GPT-5.2 ($1.75 USD Input / $14 USD Output).
Monthly Hardware Cost (AWS):
ml.g6.12xlarge: $4,141.44 USD (Cost per second: $0.00158)
The Test Block Cost (3B In / 500M Out): On OpenAI, billing this volume would cost $12,250 USD ($5,250 for reading + $7,000 for writing). Let’s see how much it costs to process exactly that same volume on our infrastructure:
| On ml.g6.12xlarge (Input 8,200 TPS | Output 1,120 TPS): |
- Input: $578.05 USD in machine time
- Output: $705.35 USD in machine time
- Actual AWS cost = $1,283.40 USD
Spending ~$1,285 in machine time versus $12,250 in API costs still demonstrates massive savings above 89%.
Maximum Theoretical Capacity (Server at 100% 24/7): The g6.12xlarge instance, powered by the Ada Lovelace architecture, reads tokens substantially faster, raising the processing ceiling. When saturated for a month, here is its maximum operational capacity:
- Maximum Input: 21,549 million tokens.
- Maximum Output: 2,943 million tokens.
- AWS Cost: ~$4,141.44 USD (1 monthly server)
- Equivalent GPT-5.2 Cost: $78,918 USD ($37,711 In + $41,207 Out).
- Operational ROI: ~19x
3. Heavyweight Category (122B): L40S Architecture vs GPT-5.4
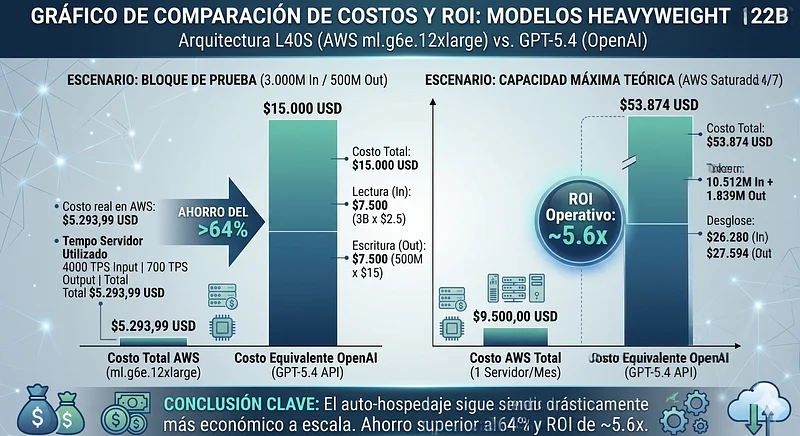
To deploy a 120B+ class model (qwen3.5 122B Non-reasoning) quantized to 4-bit (AWQ), the model weight is around 81GB of VRAM. Adding the memory needed for the KV Cache of 32 concurrent users, the previous machines would collapse due to Out Of Memory (OOM).
The optimal architectural solution is the ml.g6e.12xlarge instance, which provides 4 NVIDIA L40S GPUs, totaling 192GB of VRAM with massive 864 GB/s bandwidth per card. We compare against GPT-5.4 rates ($2.5 USD Input / $15 USD Output).
Monthly Hardware Cost (AWS):
ml.g6e.12xlarge: $9,500.00 USD (Cost per second: $0.00361)
The Test Block Cost (3B In / 500M Out): On OpenAI (GPT-5.4), this volume demands exactly $15,000 USD ($7,500 for reading + $7,500 for writing). Let’s see the comparison on our dedicated server:
-
On ml.g6e.12xlarge (Input 4,000 TPS Output 700 TPS): - Input: $2,711.99 USD in machine time
- Output: $2,582.00 USD in machine time
- Actual AWS cost = $5,293.99 USD
Even in the heaviest commercial model category, our own infrastructure is nearly 65% cheaper for this specific batch.
Maximum Theoretical Capacity (Server at 100% 24/7): When saturating this machine 24/7, we get a 5.6x multiplier ROI. We pay $9,500 for dedicated hardware to get nearly $54K worth of API billing value:
- Maximum Input: 10,512 million tokens.
- Maximum Output: 1,839 million tokens.
- Equivalent GPT-5.4 Cost: $53,874 USD ($26,280 In + $27,594 Out).
- Operational ROI: ~5.6x
Scaling and Concurrency
It’s important to note that these numbers assume a single server serving 32 users simultaneously to keep latency as low as possible. In real life, this is much more flexible.
The server can handle more concurrent users if we accept lowering the Tokens Per Second (TPS) per user, as long as we don’t drop below human reading speed (TPOT).
Additionally, when using AWS SageMaker we’re not dependent on a single node. We configure Auto-Scaling policies to automatically spin up more instances during traffic spikes, and shut them down when there are no users. This allows us to scale on demand without inflating costs too much. However, it’s worth considering that new node scaling takes between 5 and 15 minutes to be ready (container pull, LLM weight download, VRAM loading, etc.).
Speed and User Experience (UX)
The numbers speak for themselves, but managing your own servers also improves the user experience. OpenAI’s commercial APIs are multi-tenant environments; your traffic competes in public queues and goes through rate limits, introducing latency spikes you can’t control.
Having your own endpoints on SageMaker:
- Instant TTFT: Since there are no global queues, the time until the first word appears drops to milliseconds. The app feels fast.
- Constant TPOT: GPUs like the L40S output text much faster than a user can read.
- Network Latency: Having inference in the same AWS region as your database and backend eliminates the network delays of making requests to the public internet.
OpenAI model output speeds:
- GPT-4.1: 37 TPS
- GPT-5.2: 46 TPS
- GPT-5.4: 43 TPS
The qwen3.5 model on AWS with 32 concurrent users on 2 servers:
- 9B: 70 TPS (35 x 2)
- 35B: 70 TPS (35 x 2)
- 122B: 43.74 TPS (21.87 x 2)
With 16 concurrent users:
- 9B: 140 TPS (70 x 2)
- 35B: 140 TPS (70 x 2)
- 122B: 87.48 TPS (43.74 x 2)
With 8 concurrent users:
- 9B: 280 TPS (140 x 2)
- 35B: 280 TPS (140 x 2)
- 122B: 174.96 TPS (87.48 x 2)
As we can see, server capacity is finite and output TPS depends on the number of simultaneous requests the server may be experiencing at the moment of responding.
Maximizing Hardware Investment
A technical detail that often goes unnoticed when renting large instances (like the ml.g6e.12xlarge with its 4 GPUs and 192GB total VRAM) is that you’re not obligated to dedicate all that hardware to a single monolithic model.
If your architecture requires it, you can consolidate workloads to squeeze the investment to the max. For example, if the quantized 122B model occupies about 81GB of VRAM, you have more than half the memory free. That leftover space allows you to run additional models on the same machine without paying an extra dollar.
You could have the heavyweight model (122B) handling complex reasoning tasks, while running alongside it, on the same server, a couple of smaller and faster models (like 9B versions) dedicated exclusively to classification, data extraction, or routing tasks.
Even if you use techniques like LoRA (Low-Rank Adaptation), engines like vLLM allow you to load a single base model in memory and apply multiple adapters on the fly for different use cases. Basically, you stop paying for “the model” and become the owner of raw “compute capacity,” squeezing every gigabyte of memory and further multiplying the ROI versus commercial APIs.
Real Costs and Network
The mathematical analysis above focuses on the primary and heaviest expense: pure compute (instance hourly rate). However, in a real production deployment, the final bill will have marginal variation due to peripheral costs inherent to the cloud ecosystem.
When spinning up endpoints on SageMaker, you must consider minor additional charges. These include the EBS storage needed to host model weights and containers, as well as possible Data Transfer In charges depending on how you feed data into the system.
But this is where architecture design works in your favor: the dreaded Data Transfer Out, which is usually the most aggressive and destructive hidden cost in the cloud, is neutralized. If your backend or microservices query the model operating strictly within the same VPC (Virtual Private Cloud), the outbound transfer of those millions of generated tokens is free.
All the heavy text volume transits securely through AWS’s internal network. This ensures that peripheral costs remain at a minimum percentage and don’t alter the overwhelming ROI that dedicated hardware offers versus public APIs.
Savings Plans
It’s possible to save up to 43% without paying any USD upfront with Savings Plans. To do this, we simply choose a 3-year duration, no upfront costs, define the hourly USD amount we’d like to save, and all additional spending will be charged at the on-demand price. For example, if we know we’ll be using 9B models or higher for at least 3 years, we can define an hourly savings of $1,522 USD (price of 2 ml.g5.xlarge monthly instances).
Usage examples with 3-year commitment:
ml.g5.xlargenormal monthly $1,014 USD (Cost per second: $0.000386), with Savings Plans $547.92 USD (Cost per second: $0.0002084)ml.g6.12xlargenormal monthly $4,141.44 USD (Cost per second: $0.00158), with Savings Plans $2,3767.15 USD (Cost per second: $0.009043)ml.g6e.12xlargenormal monthly $9,500.00 USD (Cost per second: $0.00361), with Savings Plans $4,895.44 USD (Cost per second: $0.00186)
Resilience
At a minimum for a real production environment, we must maintain two instances in two AZs (availability zones) to maintain high service availability. This represents double the server cost, but guarantees double the TPS, which ensures the ROI described above, since we’ll have more token interpretation and generation capacity.
Serverless Option with Amazon Bedrock
Amazon Bedrock provides access to open-source open-weight models through a unified API, fully managed and serverless, without the need to manage infrastructure.
The Qwen family is already available on this platform: the four available Qwen3 models include Qwen3-Coder-480B-A35B-Instruct, Qwen3-Coder-30B-A3B-Instruct, Qwen3-235B-A22B-Instruct-2507, and Qwen3-32B Dense, with both Mixture-of-Experts (MoE) and dense architectures.
Bedrock’s proposal is simple: you pay exclusively for the tokens you consume, without committing to a dedicated server. Amazon Bedrock uses a token-based pricing model, paying per million tokens processed, where input tokens are always cheaper than output tokens, typically between 3 and 5 times cheaper. As a reference, the Qwen3-Coder-480B model on Bedrock is priced at $1.50 per million input tokens and $7.50 per million output tokens.
What this means is: if you don’t want to pay for fixed or hourly servers, you can still use open-weight models with Amazon Bedrock at prices much lower than traditional providers like OpenAI.
Comparison
- Input: 21,549 million tokens.
- Output: 2,943 million tokens.
- Qwen3 235B A22B 2507 on Amazon Bedrock: $7,331.069 USD ($4,740.912 In + $2,590.157 Out)
- qwen3.5 35B on SageMaker: ~$8,282.88 USD (2 monthly servers)
- qwen3.5 9B on SageMaker: ~$2,028.1 USD (2 monthly servers)
- Equivalent GPT-5.2 Cost: $78,918 USD ($37,711 In + $41,207 Out).
As we can see, Qwen3 235B A22B 2507 on Amazon Bedrock can be cheaper than even Qwen3.5 35B on SageMaker, however the model is inferior in intelligence and speed. As we can see in this comparison, even the 9B Qwen3.5 model on SageMaker is smarter, faster, and cheaper than Bedrock. This demonstrates that model generations matter more than parameter size when determining intelligence and task execution capability.
When Bedrock Makes Sense
Bedrock doesn’t compete directly with a self-deployment on SageMaker; rather, it fits into a very specific stage of the product lifecycle.
If during your testing any Amazon Bedrock model serves you perfectly in intelligence and response times, I believe it would be a better option than dedicated SageMaker servers, mainly because Bedrock is ideal for:
- Extended validation phases. When you’ve passed the prototype stage but still don’t have certainty about production volume. You pay only for what you use, without committing to a server that may sit idle.
- Very irregular or low traffic. If your application has sporadic peaks separated by hours of inactivity, paying for a dedicated 24/7 server destroys the ROI. Bedrock bills per millisecond of actual usage.
- Small teams without dedicated DevOps. Bedrock eliminates infrastructure management complexity with serverless access and pay-per-use. No containers to maintain, no CUDA driver updates, no error alerts at 3 AM.
- Multiple models in experimentation. With Bedrock you can use not only Amazon’s proprietary models but also open-source models like Qwen, Llama, or Mistral by simply changing the model field in your code, without additional endpoint deployments.
Conclusion
At the architecture level, the lifecycle of an AI product is quite predictable. The choice between OpenAI, Amazon Bedrock, and SageMaker is a natural progression dictated by volume and product maturity. Providers like OpenAI are the ideal entry point: frictionless, infrastructure-free, perfect for validating the idea. Bedrock occupies the middle step: it keeps you in the AWS ecosystem with open-weight models like Qwen, eliminates fixed-cost risk, and gives you flexibility to grow without commitment, although you still pay per token and share infrastructure with other customers. SageMaker is the final stage: when volume is predictable and constant, fixed cost becomes your greatest competitive advantage, giving you absolute control over latency, hardware, and margins. The signal to migrate from one stage to the next is always the same: when the current billing model starts punishing your growth, it’s time to level up.
However, if your application does well, depending on an external provider brings two critical problems. First, the pay-per-token model punishes your growth: the more users, the lower the margins. Second, you completely delegate your users’ experience to a public queue; if the third-party API gets saturated, your application becomes slow and unstable, and there’s nothing you can do about it.
Deploying robust open-weight models (like Qwen 3.5) on AWS solves both sides of the equation. On the financial side, you move from variable spending to a fixed, predictable monthly cost, achieving savings of up to 98%. On the technical side, owning the hardware eliminates latency spikes, reduces response time to milliseconds, and guarantees smooth interaction at all times.
In short: when you reach the serious production stage, spinning up your own infrastructure stops being a simple experiment to save money. It becomes the only way to ensure your business is profitable and your users have a fast, private, and reliable product no matter how much you scale.
Also read my recent post on this topic: Reducing LLM Costs by Up to 90% with Open-Weight Models