Reduzindo o Custo em Produção: Qwen 3.5 na AWS vs OpenAI
Análise técnica: AWS SageMaker vs OpenAI. Descubra por que hospedar modelos open-weights é vital para rentabilidade e latência.

As APIs gerenciadas de provedores LLM são o padrão da indústria hoje em dia. No entanto, quando uma aplicação passa da fase de protótipo para produção e precisa suportar usuários concurrentes de verdade, o modelo de cobrança por token se torna rapidamente um problema financeiro.
Para quem projeta arquiteturas em escala, migrar para modelos open-weights em infraestrutura própria vai além de uma questão de privacidade de dados. Como explorei recentemente na minha análise sobre como reduzir até 90% os custos de LLMs, trata-se de uma decisão puramente de viabilidade econômica e controle de latência.
Este artigo detalha os números exatos de custos e desempenho ao comparar a implantação da família de modelos Qwen 3.5 (9B, 35B e 122B) no AWS SageMaker Real-time Inference contra as versões comerciais da OpenAI.
O Glossário de Inferência
Antes de ver os números, revisemos as métricas que definem o desempenho de um modelo em produção:
- AWS SageMaker Real-time Inference: O ambiente que usaremos para criar os endpoints dedicados. Permite implantar contêineres otimizados mantendo o controle do hardware.
- TPS (Tokens Per Second): O throughput puro do hardware. Quantos tokens a GPU processa por segundo.
- TTFT (Time To First Token): O tempo desde que o usuário envia o prompt até que o servidor devolve a primeira palavra. Define quão rápido o sistema parece.
- TPOT (Time Per Output Token): A velocidade com que o texto é gerado. O olho humano lê a cerca de 5–8 tokens por segundo; nosso sistema precisa ser mais rápido que isso.
- Continuous Batching: A técnica dos motores modernos (como vLLM ou TGI) que permite processar múltiplas requisições concurrentes, sobrepondo a leitura do contexto de um usuário com a geração de palavras de outro para aproveitar ao máximo a VRAM.
Análise de Build vs. Buy
O Cenário Base
Para realizar esses cálculos, modelamos o seguinte ambiente de alta demanda:
- Carga de trabalho: 32 usuários concurrentes exigindo do servidor 24/7.
- Tempo operacional: 1 mês completo (2.628.000 segundos ou 730 horas).
- Tráfego por ciclo analisado: 3 bilhões de tokens de Input (leitura) e 500 milhões de tokens de Output (geração).
1. Categoria 9B: Qwen 3.5 vs GPT-4.1
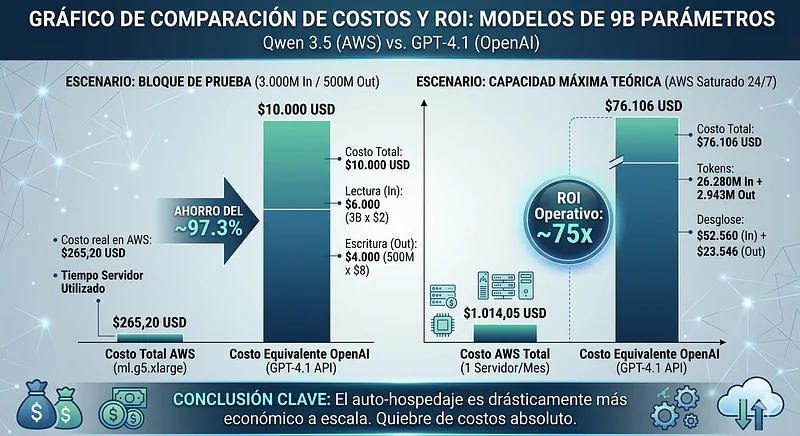
Para modelos de 9 bilhões de parâmetros (qwen3.5 9B Non-reasoning), as instâncias base da série G da AWS são suficientes. Comparamos os custos assumindo as tarifas do GPT-4.1 ($2 USD por 1M Input / $8 USD por 1M Output).
Custo Mensal de Hardware (AWS):
ml.g6.xlarge: $811,22 USD (Custo por segundo: $0,000309)ml.g5.xlarge: $1.014,05 USD (Custo por segundo: $0,000386)
O Custo do Bloco de Teste (3B In / 500M Out): Se executarmos nossa carga base na infraestrutura própria, calculamos a fração de tempo de servidor utilizada e seu custo equivalente. Na OpenAI, este mesmo bloco custaria $10.000 USD ($6.000 de leitura + $4.000 de escrita). Vejamos quanto custa processar exatamente esse mesmo volume em nosso hardware dedicado calculando a fração de tempo utilizada:
No ml.g6.xlarge:
- Input (10.000 TPS) = $92,7 USD em tempo de máquina
- Output (900 TPS) = $171,5 USD em tempo de máquina
- Custo real na AWS = $264,2 USD
No ml.g5.xlarge:
- Input (10.000 TPS) = $115,8 USD
- Output (1.120 TPS) = $172,5 USD
- Custo real na AWS = $265,2 USD
Gastar ~$265 dólares de tempo de máquina contra $10.000 dólares de API demonstra uma quebra absoluta na curva de custos.
Capacidade Máxima Teórica (Servidor a 100% 24/7): Levando o hardware ao limite durante todo o mês, o valor dos tokens processados frente às tarifas da OpenAI é avassalador. Se saturarmos a ml.g5.xlarge, a matemática de produção é a seguinte:
- Input Máximo: 26.280 Milhões de tokens.
- Output Máximo: 2.943 Milhões de tokens.
- Custo na AWS: ~$1.014,05 USD (1 servidor mensal)
- Custo Equivalente no GPT-4.1: $76.106 USD ($52.560 In + $23.546 Out).
- Retorno Operacional (ROI): ~75x
2. Categoria 35B: Qwen 3.5 vs GPT-5.2
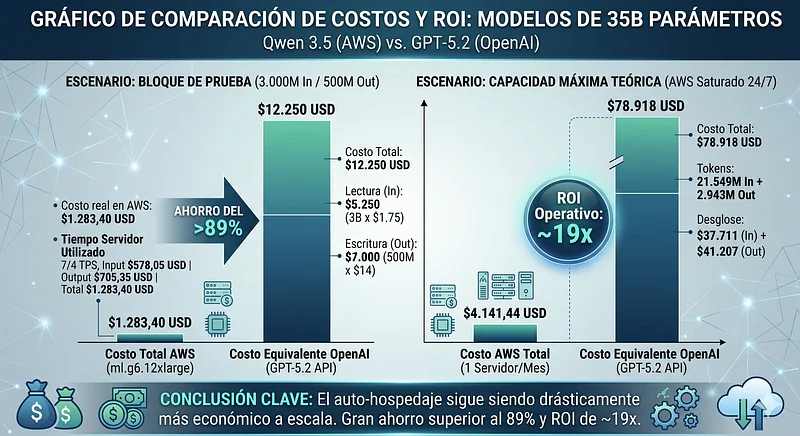
Pular para 35B (qwen3.5 35B Non-reasoning) melhora o raciocínio lógico, mas requer mais VRAM e memória unificada. Comparamos contra o GPT-5.2 ($1,75 USD Input / $14 USD Output).
Custo Mensal de Hardware (AWS):
ml.g6.12xlarge: $4.141,44 USD (Custo por segundo: $0,00158)
O Custo do Bloco de Teste (3B In / 500M Out): Na OpenAI, faturar este volume custaria $12.250 USD ($5.250 de leitura + $7.000 de escrita). Vejamos quanto custa processar exatamente esse mesmo volume em nossa infraestrutura:
| No ml.g6.12xlarge (Input 8.200 TPS | Output 1.120 TPS): |
- Input: $578,05 USD em tempo de máquina
- Output: $705,35 USD em tempo de máquina
- Custo real na AWS = $1.283,40 USD
Gastar ~$1.285 dólares de tempo de máquina contra $12.250 dólares de API ainda demonstra uma economia massiva superior a 89%.
Capacidade Máxima Teórica (Servidor a 100% 24/7): A instância g6.12xlarge, impulsionada pela arquitetura Ada Lovelace, lê tokens substancialmente mais rápido, elevando o teto de processamento. Ao saturá-la durante um mês, esta é sua capacidade máxima operacional:
- Input Máximo: 21.549 Milhões de tokens.
- Output Máximo: 2.943 Milhões de tokens.
- Custo na AWS: ~$4.141,44 USD (1 servidor mensal)
- Custo Equivalente no GPT-5.2: $78.918 USD ($37.711 In + $41.207 Out).
- Retorno Operacional (ROI): ~19x
3. Categoria Heavyweight (122B): Arquitetura L40S vs GPT-5.4
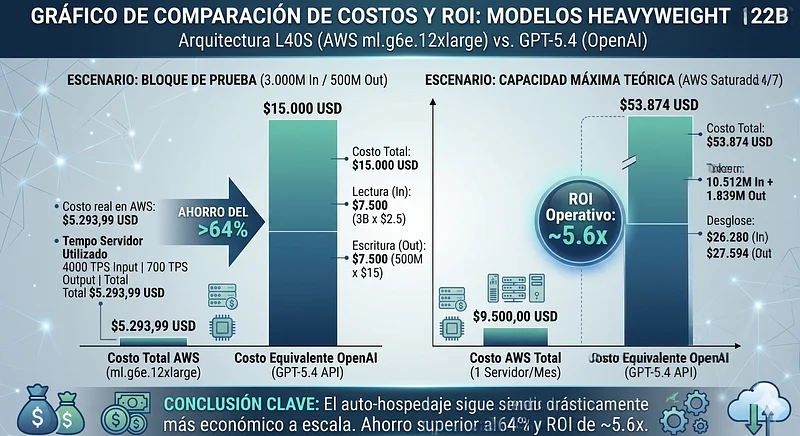
Para implantar um modelo de classe 120B+ (qwen3.5 122B Non-reasoning) quantizado em 4-bit (AWQ), o peso do modelo fica em torno de 81GB de VRAM. Somando a memória necessária para o KV Cache de 32 usuários concurrentes, as máquinas anteriores colapsariam por Out Of Memory (OOM).
A solução arquitetônica ótima é a instância ml.g6e.12xlarge, que fornece 4 GPUs NVIDIA L40S, totalizando 192GB de VRAM com uma largura de banda massiva de 864 GB/s por placa. Comparamos contra as tarifas do GPT-5.4 ($2,5 USD Input / $15 USD Output).
Custo Mensal de Hardware (AWS):
ml.g6e.12xlarge: $9.500,00 USD (Custo por segundo: $0,00361)
O Custo do Bloco de Teste (3B In / 500M Out): Na OpenAI (GPT-5.4), este volume exige exatamente $15.000 USD ($7.500 de leitura + $7.500 de escrita). Vejamos a comparação em nosso servidor dedicado:
-
No ml.g6e.12xlarge (Input 4.000 TPS Output 700 TPS): - Input: $2.711,99 USD em tempo de máquina
- Output: $2.582,00 USD em tempo de máquina
- Custo real na AWS = $5.293,99 USD
Ainda na categoria mais pesada de modelos comerciais, a infraestrutura própria é quase 65% mais barata para este lote específico.
Capacidade Máxima Teórica (Servidor a 100% 24/7): Ao saturar esta máquina 24/7, obtemos um ROI multiplicador de 5,6x. Pagamos $9.500 por hardware dedicado para obter quase $54K de valor em faturamento de API:
- Input Máximo: 10.512 Milhões de tokens.
- Output Máximo: 1.839 Milhões de tokens.
- Custo Equivalente no GPT-5.4: $53.874 USD ($26.280 In + $27.594 Out).
- Retorno Operacional (ROI): ~5,6x
Escalabilidade e Concorrência
É importante notar que esses números assumem um único servidor respondendo a 32 usuários ao mesmo tempo para manter a latência o mais baixa possível. Na vida real, isso é muito mais flexível.
O servidor suporta mais usuários concurrentes se aceitarmos diminuir um pouco os Tokens Per Second (TPS) por usuário, desde que não caia abaixo da velocidade de leitura humana (TPOT).
Além disso, ao usar AWS SageMaker não dependemos de um único nó. Configuramos políticas de Auto-Scaling para levantar mais instâncias automaticamente se houver picos de tráfego, e desligá-las quando não há usuários. Isso nos permite escalar sob demanda sem inflar demais os custos. No entanto, é preciso considerar que o tempo de escalonamento do novo nó leva entre 5 e 15 minutos para ficar pronto (pull do contêiner, download dos pesos do LLM, carregamento na VRAM, etc.).
A Velocidade e a Experiência do Usuário (UX)
Os números falam por si só, mas administrar seus próprios servidores também melhora a experiência do usuário. As APIs comerciais da OpenAI são ambientes multi-tenant; seu tráfego compete em filas públicas e passa por rate-limits, o que introduz picos de latência que você não pode controlar.
Ao ter seus próprios endpoints no SageMaker:
- TTFT Instantâneo: Como não há filas globais, o tempo até que a primeira palavra apareça cai para milissegundos. A app parece rápida.
- TPOT Constante: GPUs como a L40S produzem texto muito mais rápido do que um usuário consegue ler.
- Latência de Rede: Ter a inferência na mesma região da AWS que seu banco de dados e seu backend elimina os atrasos de rede de fazer requisições à internet pública.
Velocidades de output dos modelos da OpenAI:
- GPT-4.1: 37 TPS
- GPT-5.2: 46 TPS
- GPT-5.4: 43 TPS
O modelo qwen3.5 na AWS com 32 usuários concurrentes em 2 servidores:
- 9B: 70 TPS (35 x 2)
- 35B: 70 TPS (35 x 2)
- 122B: 43,74 TPS (21,87 x 2)
Com 16 usuários concurrentes:
- 9B: 140 TPS (70 x 2)
- 35B: 140 TPS (70 x 2)
- 122B: 87,48 TPS (43,74 x 2)
Com 8 usuários concurrentes:
- 9B: 280 TPS (140 x 2)
- 35B: 280 TPS (140 x 2)
- 122B: 174,96 TPS (87,48 x 2)
Como podemos ver, a capacidade dos servidores é finita e a capacidade de TPS em output vai depender da quantidade de solicitações simultâneas que o servidor pode estar experimentando no instante de responder a solicitação.
Maximizando o Investimento em Hardware
Um detalhe técnico que costuma passar despercebido ao alugar instâncias de grande porte (como a ml.g6e.12xlarge com suas 4 GPUs e 192GB de VRAM total) é que você não é obrigado a dedicar todo esse hardware a um único modelo monolítico.
Se sua arquitetura exigir, você pode consolidar cargas de trabalho para extrair o máximo do investimento. Por exemplo, se o modelo de 122B quantizado ocupa cerca de 81GB de VRAM, você tem mais da metade da memória livre. Esse espaço restante permite rodar modelos adicionais na mesma máquina sem pagar um dólar extra.
Você poderia ter o modelo heavyweight (122B) atendendo tarefas de raciocínio complexo, e rodando ao lado, no mesmo servidor, um par de modelos mais rápidos e leves (como versões de 9B) dedicados exclusivamente a tarefas de classificação, extração de dados ou routing.
Mesmo se você usar técnicas como LoRA (Low-Rank Adaptation), motores como vLLM permitem carregar um único modelo base na memória e aplicar múltiplos adaptadores em tempo real para diferentes casos de uso. Basicamente, você deixa de pagar por “o modelo” e passa a ser dono de uma “capacidade de computação” bruta, extraindo cada gigabyte de memória e multiplicando ainda mais o ROI frente às APIs comerciais.
Custos Reais e Rede
A análise matemática acima se concentra no gasto principal e mais pesado: o computo puro (preço por hora da instância). No entanto, em uma implantação de produção real, a fatura final terá uma variação marginal devido a custos periféricos próprios do ecossistema de nuvem.
Ao criar endpoints no SageMaker, você deve contemplar cobranças adicionais menores. Estas incluem o armazenamento EBS necessário para hospedar os pesos do modelo e os contêineres, assim como possíveis cobranças por Data Transfer In dependendo de como você injeta as informações no sistema.
Mas é aqui que o design da arquitetura joga a seu favor: o temido Data Transfer Out, que costuma ser o custo oculto mais agressivo e destrutivo na nuvem, é neutralizado. Se seu backend ou microsserviços consultam o modelo operando estritamente dentro da mesma VPC (Virtual Private Cloud), a transferência de saída desses milhões de tokens gerados é gratuita.
Todo o volume pesado de texto transita de forma segura pela rede interna da AWS. Isso garante que os custos periféricos se mantenham em uma porcentagem mínima e não alterem o ROI avassalador que o hardware dedicado oferece frente às APIs públicas.
Savings Plans
É possível economizar até 43% sem pagar nenhum USD adiantado com Savings Plans. Para isso, basta escolher a duração de 3 anos, sem custos iniciais, definir o montante de USD por hora que gostaria de economizar, e todo gasto adicional será cobrado com o preço sob demanda. Por exemplo, se sabemos que vamos utilizar modelos 9B ou superior por no mínimo 3 anos, podemos definir uma economia por hora de $1.522 USD (preço de 2 instâncias ml.g5.xlarge mensais).
Exemplos de uso com compromisso de 3 anos:
ml.g5.xlargemensal normal $1.014 USD (Custo por segundo: $0,000386), com Saving Plans $547,92 USD (Custo por segundo: $0,0002084)ml.g6.12xlargemensal normal $4.141,44 USD (Custo por segundo: $0,00158), com Saving Plans $2.3767,15 USD (Custo por segundo: $0,009043)ml.g6e.12xlargemensal normal $9.500,00 USD (Custo por segundo: $0,00361), com Saving Plans $4.895,44 USD (Custo por segundo: $0,00186)
Resiliência
No mínimo para um ambiente de produção real, devemos manter duas instâncias em duas AZs (zonas de disponibilidade) para manter a alta disponibilidade do serviço. Isso representa um custo dobrado de servidor, mas garante o dobro de TPS, o que garante o ROI descrito anteriormente, uma vez que teremos mais capacidade de interpretação e geração de tokens.
Opção Serverless com Amazon Bedrock
O Amazon Bedrock fornece acesso a modelos open-weight de código aberto através de uma API unificada, de forma completamente gerenciada e serverless, sem necessidade de gerenciar infraestrutura.
A família Qwen já está disponível nesta plataforma: os quatro modelos Qwen3 disponíveis incluem Qwen3-Coder-480B-A35B-Instruct, Qwen3-Coder-30B-A3B-Instruct, Qwen3-235B-A22B-Instruct-2507 e Qwen3-32B Dense, com arquiteturas tanto Mixture-of-Experts (MoE) quanto densa.
A proposta do Bedrock é simples: você paga exclusivamente pelos tokens que consome, sem se comprometer com um servidor dedicado. O Amazon Bedrock utiliza um modelo de preços baseado em tokens, pagando por milhão de tokens processados, onde os tokens de entrada são sempre mais baratos que os de saída, tipicamente entre 3 e 5 vezes mais baratos. Como referência, o modelo Qwen3-Coder-480B no Bedrock tem um preço de $1,50 por milhão de tokens de entrada e $7,50 por milhão de tokens de saída.
O que isso significa é: se você não quer pagar por servidores fixos ou por hora, ainda pode utilizar modelos open-weight com o Amazon Bedrock com preços muito mais baixos que provedores tradicionais como a OpenAI.
Comparação
- Input: 21.549 Milhões de tokens.
- Output: 2.943 Milhões de tokens.
- Qwen3 235B A22B 2507 no Amazon Bedrock: $7.331,069 USD ($4.740,912 In + $2.590,157 Out)
- qwen3.5 35B no SageMaker: ~$8.282,88 USD (2 servidores mensais)
- qwen3.5 9B no SageMaker: ~$2.028,1 USD (2 servidores mensais)
- Custo Equivalente no GPT-5.2: $78.918 USD ($37.711 In + $41.207 Out).
Como podemos ver, Qwen3 235B A22B 2507 no Amazon Bedrock pode ser mais barato que até mesmo Qwen3.5 35B no SageMaker, no entanto o modelo é inferior em inteligência e velocidade. Como podemos ver nesta comparação, até mesmo o modelo de 9B do Qwen3.5 no SageMaker é mais inteligente, rápido e barato que o Bedrock. Isso demonstra que as gerações de modelos pesam mais que o tamanho dos parâmetros ao determinar a inteligência e a capacidade dos modelos na execução de tarefas.
Quando o Bedrock Faz Sentido
O Bedrock não compete diretamente com uma implantação própria no SageMaker; na verdade, ele se encaixa em uma etapa muito específica do ciclo de vida do produto.
Se durante seus testes qualquer modelo do Amazon Bedrock te atender perfeitamente em inteligência e tempos de resposta, acredito que seria uma melhor opção que servidores dedicados do SageMaker, principalmente porque o Bedrock é ideal para:
- Fases de validação estendidas. Quando você já superou o protótipo mas ainda não tem certeza sobre o volume de produção. Você paga apenas pelo que usa, sem se comprometer com um servidor que pode ficar ocioso.
- Tráfego muito irregular ou baixo. Se sua aplicação tem picos esporádicos separados por horas de inatividade, pagar por um servidor dedicado 24/7 destrói o ROI. O Bedrock fatura por milissegundo de uso real.
- Equipes pequenas sem DevOps dedicado. O Bedrock elimina a complexidade do gerenciamento de infraestrutura com acesso serverless e pagamento por consumo. Não há contêineres para manter, não há atualizações de drivers CUDA, não há alertas de erro às 3 da manhã.
- Múltiplos modelos em experimentação. Com o Bedrock você pode usar não apenas modelos proprietários da Amazon, mas também modelos open-source como Qwen, Llama ou Mistral mudando apenas o campo do modelo em seu código, sem implantações adicionais de endpoints.
Conclusão
No nível de arquitetura, o ciclo de vida de um produto com IA é bastante previsível. A escolha entre OpenAI, Amazon Bedrock e SageMaker é uma progressão natural ditada pelo volume e maturidade do seu produto. Provedores como a OpenAI são o ponto de entrada ideal: sem fricção, sem infraestrutura, perfeito para validar a ideia. O Bedrock ocupa o escalão intermediário: mantém você no ecossistema AWS com modelos open-weights como o Qwen, elimina o risco de custo fixo e dá flexibilidade para crescer sem compromissos, embora você ainda pague por token e compartilhe infraestrutura com outros clientes. O SageMaker é a etapa final: quando o volume é previsível e constante, o custo fixo se torna sua maior vantagem competitiva, dando controle absoluto sobre latência, hardware e margens. O sinal para migrar de uma etapa para a seguinte é sempre o mesmo: quando o modelo de cobrança atual começa a prejudicar seu crescimento, é hora de subir um nível.
No entanto, se sua aplicação vai bem, depender de um provedor externo traz dois problemas críticos. Primeiro, o modelo de pagamento por token prejudica seu crescimento: quanto mais usuários, menores as margens. Segundo, você delega completamente a experiência dos seus usuários a uma fila pública; se a API de terceiros fica saturada, sua aplicação se torna lenta e instável, e você não pode fazer nada a respeito.
Implantar modelos open-weight robustos (como o Qwen 3.5) na AWS resolve ambos os lados da equação. No financeiro, você passa de um gasto variável para um custo mensal fixo e previsível, alcançando economias de até 98%. No técnico, ao ser dono do hardware, você elimina os picos de latência, reduz o tempo de resposta para milissegundos e garante uma interação fluida o tempo todo.
Em resumo: quando você chega à etapa de produção séria, criar sua própria infraestrutura deixa de ser um simples experimento para economizar dinheiro. Se torna a única forma de garantir que seu negócio seja lucrativo e que seus usuários tenham um produto rápido, privado e confiável, não importa o quanto você escale.
Leia também meu post recente sobre este tema: Reduzindo até 90% os custos de LLMs com modelos open-weights