LLM-as-a-Judge: cómo construir pipelines de evaluación de IA que escalen

Los prompts en sistemas con Large Language Models (LLMs) no se comportan como código determinista. En un desarrollo de software tradicional, si modificas una función y todos los tests pasan, puedes desplegar con confianza. Con los LLMs, un cambio mínimo en el prompt para mejorar el tono de una respuesta puede, inadvertidamente, hacer que el modelo deje de extraer una entidad clave o falle al invocar una herramienta externa (tool call).
Esta regresión silenciosa es el mayor riesgo al operar IA en producción. Sin un pipeline de evaluación sistemática, iterar prompts es esencialmente una apuesta. La evaluación manual no escala, y usar métricas de similitud de texto tradicional se queda corto. El patrón LLM-as-a-Judge resuelve esto usando un modelo para evaluar a otro.
Te mostraré cómo construir un pipeline de evaluación que escale económicamente para entornos de producción, basándome en mi experiencia construyendo estos sistemas a gran escala.
El marco CC/CD: Más allá del CI/CD clásico
Cuando desarrollamos software tradicional, usamos CI/CD (Continuous Integration / Continuous Deployment), donde el objetivo es construir, probar exhaustivamente y llegar al despliegue como la meta final del ciclo. Pero para los sistemas de IA generativa, este enfoque lineal se queda corto. El nuevo modelo es el CC/CD (Continuous Calibration / Continuous Development), donde el despliegue no es el final del proceso, sino apenas una transición hacia el verdadero ajuste fino.
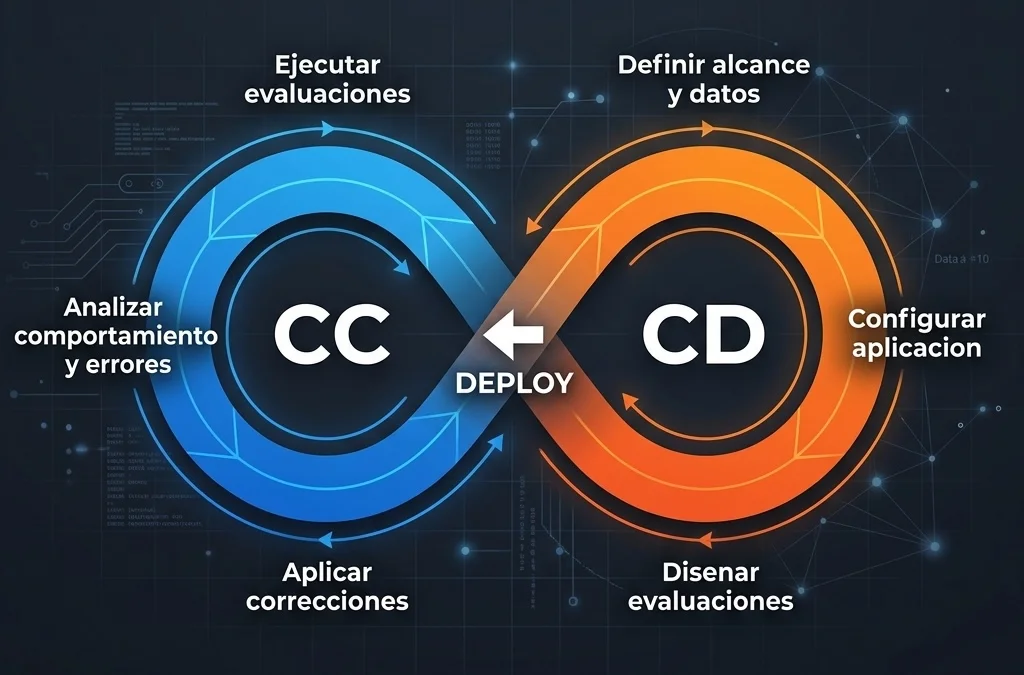
Fase de Desarrollo Continuo (Continuous Development)
- El ciclo comienza al establecer distintas versiones de un prompt enfocadas en un caso de uso particular.
- Se recopila un conjunto de datos base que contenga interacciones representativas para validar cómo debería responder el sistema.
- Configuramos métricas a medida y se determinan qué modelos actuarán como jueces para calificar los resultados.
Fase de Calibración Continua (Continuous Calibration)
- Ante cualquier ajuste en un prompt, se ejecuta una validación automatizada contra el conjunto de datos de control (ground truth).
- Se cuantifican atributos clave como la adherencia al formato, el tono y la precisión de la información usando LLMs evaluadores.
- Un cambio solo recibe luz verde para producción si logra superar las métricas de calidad establecidas previamente.
- Una vez en vivo, se monitorea el tráfico real para identificar anomalías o degradaciones sutiles.
- El proceso es cíclico. Los errores detectados en producción alimentan de vuelta el entorno de pruebas para afinar prompts y contextos poco a poco.
La calibración continua significa que asumimos que el modelo nunca es perfecto desde el día 1. Requiere ajustes empíricos basados en interacciones reales.
Evaluación Offline vs. Online
Para implementar CC/CD con éxito, debes estructurar tus evaluaciones en dos frentes complementarios:
Evaluación Offline
Es tu red de seguridad antes de desplegar. Cada vez que modificas un prompt o cambias de modelo, disparas una evaluación sobre un dataset estático y curado (ground truth).
- Contexto / Cuándo usarla Pre-despliegue, usando un dataset controlado e histórico.
- Trigger Modificación de prompt, actualización de modelo o cambio en la lógica RAG.
- Propósito Detectar y prevenir regresiones, y comparar versiones base.
- Costo a Escala Bajo (volumen fijo).
Evaluación Online
Es tu radar en producción. Usa tráfico real para puntuar siempre el rendimiento del modelo en interacciones vivas.
- Contexto / Cuándo usarla Post-despliegue, monitoreo en tiempo real con tráfico en vivo de usuarios.
- Trigger Trazas generadas por interacciones del usuario en producción (muestreo).
- Propósito Detectar degradación progresiva, monitorear la salud y alimentar el dataset Offline con nuevos edge cases.
- Costo a Escala Alto (escala con el tráfico real).
El argumento económico para modelos Open-Weights en evaluación
En mi post anterior sobre reducir costos de LLMs con modelos Open Weights y Qwen 3.5 en AWS, mencioné que la evaluación automatizada es el caso de uso perfecto para modelos desplegados en infraestructura propia.
¿Por qué? Porque aunque la evaluación Offline puede ser costosa usando APIs propietarias (ej. OpenAI, Anthropic), el verdadero quiebre económico ocurre en la evaluación Online.
Si quieres evaluar un 20% o 30% de tus trazas en producción para tener una muestra estadísticamente significativa de la calidad de tus respuestas, el costo de usar un modelo propietario para puntuar cada interacción se dispara y puede superar el costo de la inferencia principal de tu aplicación. Los modelos open-weights (como la familia Qwen 3.5 o 3.6 desplegada en AWS) no son solo una optimización de costos. Son una alternativa financieramente viable para escalar la calibración Online.
El stack: Langfuse Self-Hosted y Jueces Propios
La pieza central de nuestra arquitectura de evaluación es Langfuse. Aunque Langfuse Cloud es una excelente puerta de entrada para equipos pequeños, para entornos de producción maduros recomiendo Langfuse Self-Hosted sobre infraestructura propia (por ejemplo, en Kubernetes corporativo o AWS ECS).
¿Por qué Self-Hosted?
- Soberanía de Datos Los prompts y respuestas en producción a menudo contienen información sensible de los clientes que no debe enviarse a plataformas de observabilidad SaaS de terceros.
- Costos Predecibles Un clúster con capacidad fija para Langfuse cuesta una fracción comparado con los tiers basados en volumen a nivel empresarial.
- Validación en Producción Es el mismo patrón que he operado con éxito en producción a gran escala.
Langfuse maneja el versionado de prompts, la gestión de datasets y el registro de trazas y scores.
Jueces Pre-configurados vs. Jueces Propios
Langfuse ofrece evaluadores pre-configurados (ej. toxicidad, sentimiento), que son un gran punto de partida. Pero para que el patrón LLM-as-a-Judge sea realmente efectivo, necesitas construir jueces propios.
Un juez propio debe contener:
- Un prompt template altamente específico para tu caso de uso.
- Una rúbrica clara de puntuación (ej. de 0 a 1).
- Ejemplos few-shot del dominio de negocio (ej. qué significa un 0.2 vs un 0.9 en tu contexto específico).
Taxonomía de LLM-as-a-Judge, Métricas y Sesgos
Variantes del Juez
- Single Judge Un solo modelo evalúa una respuesta basada en una rúbrica. (Más rápido y económico).
- Pairwise Comparison El modelo recibe dos respuestas (A y B) y elige la mejor. (Mejor para A/B testing).
- Reference-Based (Ground Truth) El modelo compara la respuesta generada con una respuesta ideal de referencia.
Métricas Clave
Puedes diseñar tus propios prompts de evaluación para métricas como:
- Relevancia ¿Responde la salida a la pregunta del usuario sin divagar?
- Coherencia ¿Es la respuesta lógicamente sólida de principio a fin?
- Faithfulness (Fidelidad en RAG) ¿La respuesta se basa estrictamente en el contexto provisto o alucina información?
- Tono/Estilo ¿La respuesta mantiene la voz definida de la marca corporativa?
- Adherencia al Formato ¿Respetó el modelo el formato solicitado (ej. JSON estricto sin preámbulos)?
Prompt template de ejemplo para Faithfulness (Single Judge):
Eres un evaluador experto. Analiza si la RESPUESTA se basa únicamente en el CONTEXTO provisto.
No evalúes si la respuesta es correcta en el mundo real, solo si se infiere directamente del contexto.
[CONTEXTO]
[RESPUESTA]
Evalúa en una escala de 0.0 (totalmente alucinado o no relacionado) a 1.0 (perfectamente fiel al contexto).
Devuelve tu evaluación en formato JSON: {"score": 0.x, "reasoning": "tu justificación breve"}
Un score bajo en Faithfulness indica un alto riesgo de alucinación y la necesidad inmediata de ajustar el prompt del sistema RAG.
Sesgos del Juez y Mitigación
Los LLMs como jueces no son perfectos e introducen sus propios sesgos:
- Position Bias En comparaciones pairwise, el modelo tiende a favorecer a la respuesta presentada primero. Mitigación Aleatorizar el orden de A y B y promediar.
- Verbosity Bias El modelo asume que una respuesta más larga es “mejor”, incluso si incluye relleno. Mitigación Añadir instrucciones explícitas en la rúbrica penalizando la verbosidad excesiva.
- Self-Enhancement Bias Si usas Llama 3 para evaluar Llama 3, tenderá a darse puntuaciones más altas a sí mismo. Mitigación Usa un modelo juez de una familia diferente al evaluado (ej. evaluar salidas de OpenAI usando Qwen).
Checklist de Verificación de Sesgos
- El orden de las opciones en las evaluaciones Pairwise es aleatorio.
- La rúbrica penaliza explícitamente respuestas largas e innecesarias (Verbosity Bias).
- El modelo juez pertenece a una familia o versión distinta al modelo generador.
- El juez devuelve una justificación o razonamiento (Chain-of-Thought) antes del score numérico.
Implementación con Qwen 3.x y Langfuse SDK
Para el modelo juez local, recomiendo la familia Qwen 3.x por su excelente relación calidad-precio y capacidades multilingües.
¿Qwen 3.5 o 3.6?
- Elige Qwen 3.5 (72B o 32B) si vas a evaluar altos volúmenes de trazas Online y necesitas un balance óptimo entre rendimiento (TPS) y presupuesto de infraestructura.
- Elige Qwen 3.6 si estás evaluando dominios muy técnicos, razonamiento complejo o matemáticas, donde necesitas la mayor precisión posible sin importar una ligera penalización en costo de computación.
En lugar de construir scripts complejos y aislados, la mejor práctica es orquestar este proceso con pipelines en Jenkins (o tu herramienta de CI/CD). Puedes configurar un pipeline que se dispare ante cualquier modificación de un prompt y ejecute un script de evaluación que haga lo siguiente:
- Recupera el prompt modificado desde Langfuse.
- Recupera el dataset controlado de pruebas desde Langfuse.
- Corre el prompt contra los datos en el dataset de pruebas.
- Genera las trazas de las ejecuciones en Langfuse asociándolas a un tag o label en particular.
- Registra los experimentos en Langfuse, enlazando las trazas generadas previamente.
- Ejecuta la evaluación: Langfuse ejecuta los LLM-as-a-Judge contra el entorno y los tags de las ejecuciones (Evaluación Online controlada).
- Valida umbrales de calidad para aprobar o rechazar la modificación del prompt.
Análisis de costos: el punto de inflexión
Veamos los números detrás del argumento.
Costo de Evaluación Offline
Supongamos un ciclo de CC/CD que corre una evaluación completa sobre un dataset de 1,000 interacciones por cada cambio en el prompt (asumiendo ~2,000 tokens de input y ~300 de output por evaluación).
Modelo Propietario (Premium)
- Costo Input (por 1M): ~$5.00
- Costo Output (por 1M): ~$15.00
- Costo de 1,000 Evaluaciones: ~$14.50 por run
Qwen 3.x (Infraestructura propia)
- Costo Input (por 1M): Fijo (amortizado)
- Costo Output (por 1M): Fijo (amortizado)
- Costo de 1,000 Evaluaciones: Marginal (~$0)
Para Offline, el ahorro es atractivo pero no determinante. Pero en Online la historia cambia.
Costo de Evaluación Online (Calibración en Producción)
Si tienes una aplicación que genera 1,000,000 de trazas al mes, y quieres aplicar CC/CD evaluando una muestra representativa:
Muestreo del 10% de las trazas
- Volumen Evaluado / Mes: 100,000 evals
- Costo API Propietaria ($14.5/1K): ~$1,450 / mes
- Costo Infra Propia (Qwen): Servidor Fijo (~$1,000/mes)
Muestreo del 20% de las trazas
- Volumen Evaluado / Mes: 200,000 evals
- Costo API Propietaria ($14.5/1K): ~$2,900 / mes
- Costo Infra Propia (Qwen): Servidor Fijo (~$1,000/mes)
Muestreo del 30% de las trazas
- Volumen Evaluado / Mes: 300,000 evals
- Costo API Propietaria ($14.5/1K): ~$4,350 / mes
- Costo Infra Propia (Qwen): Servidor Fijo (~$1,000/mes)
El punto de inflexión es claro: tan pronto escalas el monitoreo continuo en producción, depender de APIs propietarias para LLM-as-a-Judge destruye tus márgenes operativos. Usar un modelo open-weights te da la libertad de evaluar agresivamente en Online sin miedo a la factura a fin de mes.
Conclusión
La madurez en la ingeniería de IA no se trata de escribir el “prompt perfecto”. Se trata de construir un sistema que te permita saber objetivamente cuándo un prompt es mejor que el anterior. El marco CC/CD, impulsado por Langfuse Self-Hosted y modelos Open-Weights como Qwen 3.x como jueces, permite precisamente eso.
Las evaluaciones Offline aseguran que no rompas nada al desplegar. Las evaluaciones Online te garantizan que mantienes el pulso de la realidad en producción. Si logras integrar ambas, transformarás los prompts de “cadenas de texto mágicas” a verdaderos componentes de software controlados, calibrados y mejorables.
Si quieres profundizar en cómo se ve este flujo aplicado en un caso de negocio real, te recomiendo leer mi artículo invitado detallando el marco CC/CD. Y si estás buscando optimizar tu stack de inferencia, revisa mis posts previos sobre el impacto de usar modelos Open Weights en lugar de APIs propietarias.
¿Cómo estás evaluando tus prompts en producción hoy? El CC/CD podría ser tu siguiente paso natural.