LLM-as-a-Judge: how to build scalable AI evaluation pipelines

Prompts in systems with Large Language Models (LLMs) don’t behave like deterministic code. In traditional software development, if you modify a function and all tests pass, you can deploy with confidence. With LLMs, a minimal change in the prompt to improve the tone of a response can inadvertently cause the model to stop extracting a key entity or fail to invoke an external tool (tool call).
This silent regression is the biggest risk when operating AI in production. Without a systematic evaluation pipeline, iterating on prompts is essentially a gamble. Manual evaluation doesn’t scale, and using traditional text similarity metrics falls short. The LLM-as-a-Judge pattern solves this by using one model to evaluate another.
I’ll show you how to build an evaluation pipeline that scales economically for production environments, based on my experience building these systems at scale.
The CC/CD Framework: Beyond classic CI/CD
When we develop traditional software, we use CI/CD (Continuous Integration / Continuous Deployment), where the goal is to build, test exhaustively, and reach deployment as the final objective of the cycle. But for generative AI systems, this linear approach falls short. The new model is CC/CD (Continuous Calibration / Continuous Development), where deployment is not the end of the process but merely a transition toward the true fine-tuning.
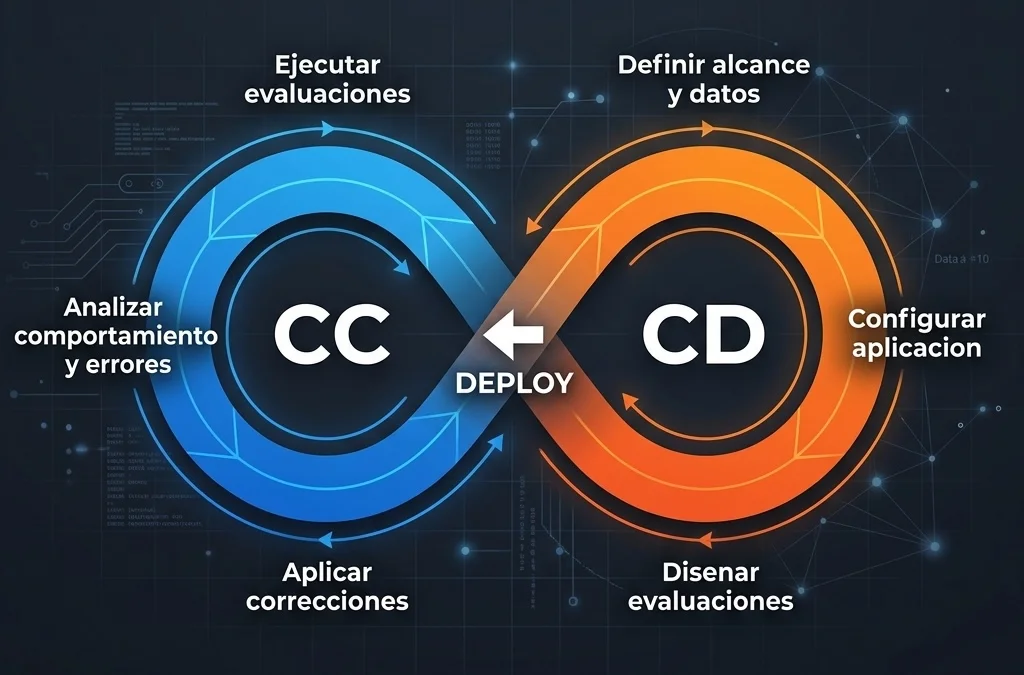
Continuous Development Phase
- The cycle begins by establishing different versions of a prompt focused on a particular use case.
- A baseline dataset is collected containing representative interactions to validate how the system should respond.
- Custom metrics are configured and models are designated to act as judges for scoring the results.
Continuous Calibration Phase
- For any adjustment to a prompt, automated validation is run against the control dataset (ground truth).
- Key attributes such as format adherence, tone, and information accuracy are quantified using evaluator LLMs.
- A change only gets the green light for production if it surpasses the previously established quality metrics.
- Once live, real traffic is monitored to identify anomalies or subtle degradations.
- The process is cyclical. Errors detected in production feed back into the testing environment to gradually refine prompts and contexts.
Continuous calibration means we assume the model is never perfect from day 1. It requires empirical adjustments based on real interactions.
Offline vs. Online Evaluation
To successfully implement CC/CD, you need to structure your evaluations on two complementary fronts:
Offline Evaluation
This is your safety net before deploying. Every time you modify a prompt or switch models, you trigger an evaluation on a static, curated dataset (ground truth).
- Context / When to use it Pre-deployment, using a controlled, historical dataset.
- Trigger Prompt modification, model update, or change in RAG logic.
- Purpose Detect and prevent regressions, and compare baseline versions.
- Cost at Scale Low (fixed volume).
Online Evaluation
This is your radar in production. It uses real traffic to continuously score model performance in live interactions.
- Context / When to use it Post-deployment, real-time monitoring with live user traffic.
- Trigger Traces generated by user interactions in production (sampling).
- Purpose Detect progressive degradation, monitor health, and feed the Offline dataset with new edge cases.
- Cost at Scale High (scales with real traffic).
The economic case for Open-Weights models in evaluation
In my previous post on reducing LLM costs with Open Weights models and Qwen 3.5 on AWS, I mentioned that automated evaluation is the perfect use case for models deployed on your own infrastructure.
Why? Because although Offline evaluation can be expensive using proprietary APIs (e.g., OpenAI, Anthropic), the real economic breakthrough happens in Online evaluation.
If you want to evaluate 20% or 30% of your traces in production to have a statistically significant sample of your response quality, the cost of using a proprietary model to score each interaction skyrockets and can exceed the cost of your application’s main inference. Open-weights models (like the Qwen 3.5 or 3.6 family deployed on AWS) are not just a cost optimization. They are a financially viable alternative for scaling Online calibration.
The stack: Langfuse Self-Hosted and Custom Judges
The centerpiece of our evaluation architecture is Langfuse. Although Langfuse Cloud is an excellent entry point for small teams, for mature production environments I recommend Langfuse Self-Hosted on your own infrastructure (e.g., on corporate Kubernetes or AWS ECS).
Why Self-Hosted?
- Data Sovereignty Prompts and responses in production often contain sensitive customer information that should not be sent to third-party SaaS observability platforms.
- Predictable Costs A fixed-capacity cluster for Langfuse costs a fraction compared to enterprise-level volume-based tiers.
- Production Validation This is the same pattern I have successfully operated in production at scale.
Langfuse handles prompt versioning, dataset management, and trace and score logging.
Pre-configured Judges vs. Custom Judges
Langfuse offers pre-configured evaluators (e.g., toxicity, sentiment), which are a great starting point. But for the LLM-as-a-Judge pattern to be truly effective, you need to build custom judges.
A custom judge must contain:
- A prompt template highly specific to your use case.
- A clear scoring rubric (e.g., 0 to 1).
- Few-shot examples from the business domain (e.g., what a 0.2 vs a 0.9 means in your specific context).
Taxonomy of LLM-as-a-Judge, Metrics, and Biases
Judge Variants
- Single Judge A single model evaluates a response based on a rubric. (Faster and cheaper).
- Pairwise Comparison The model receives two responses (A and B) and chooses the better one. (Better for A/B testing).
- Reference-Based (Ground Truth) The model compares the generated response with an ideal reference response.
Key Metrics
You can design your own evaluation prompts for metrics such as:
- Relevance Does the output address the user’s question without digressing?
- Coherence Is the response logically sound from start to finish?
- Faithfulness Does the response rely strictly on the provided context or does it hallucinate information?
- Tone/Style Does the response maintain the defined corporate brand voice?
- Format Adherence Did the model respect the requested format (e.g., strict JSON without preambles)?
Example prompt template for Faithfulness (Single Judge):
You are an expert evaluator. Analyze whether the RESPONSE is based solely on the provided CONTEXT.
Do not evaluate whether the response is correct in the real world, only whether it is directly inferred from the context.
[CONTEXT]
[RESPONSE]
Evaluate on a scale from 0.0 (completely hallucinated or unrelated) to 1.0 (perfectly faithful to the context).
Return your evaluation in JSON format: {"score": 0.x, "reasoning": "your brief justification"}
A low score in Faithfulness indicates a high risk of hallucination and the immediate need to adjust the RAG system prompt.
Judge Biases and Mitigation
LLMs as judges are not perfect and introduce their own biases:
- Position Bias In pairwise comparisons, the model tends to favor the response presented first. Mitigation Randomize the order of A and B and average.
- Verbosity Bias The model assumes a longer response is “better,” even if it includes filler. Mitigation Add explicit instructions in the rubric penalizing excessive verbosity.
- Self-Enhancement Bias If you use Llama 3 to evaluate Llama 3, it will tend to give itself higher scores. Mitigation Use a judge model from a different family than the one being evaluated (e.g., evaluate OpenAI outputs using Qwen).
Bias Verification Checklist
- The order of options in Pairwise evaluations is randomized.
- The rubric explicitly penalizes long and unnecessary responses (Verbosity Bias).
- The judge model belongs to a different family or version than the generator model.
- The judge returns a justification or reasoning (Chain-of-Thought) before the numerical score.
Implementation with Qwen 3.x and Langfuse SDK
For the local judge model, I recommend the Qwen 3.x family for its excellent quality-price ratio and multilingual capabilities.
Qwen 3.5 or 3.6?
- Choose Qwen 3.5 (72B or 32B) if you’re going to evaluate high volumes of Online traces and need an optimal balance between performance (TPS) and infrastructure budget.
- Choose Qwen 3.6 if you’re evaluating highly technical domains, complex reasoning, or mathematics, where you need the highest possible accuracy regardless of a slight penalty in computation cost.
Instead of building complex, isolated scripts, the best practice is to orchestrate this process with Jenkins pipelines (or your CI/CD tool). You can configure a pipeline that triggers on any prompt modification and runs an evaluation script that does the following:
- Retrieves the modified prompt from Langfuse.
- Retrieves the controlled test dataset from Langfuse.
- Runs the prompt against the data in the test dataset.
- Generates traces of the executions in Langfuse, associating them with a particular tag or label.
- Logs the experiments in Langfuse, linking the previously generated traces.
- Runs the evaluation: Langfuse executes the LLM-as-a-Judge against the environment and execution tags (controlled Online evaluation).
- Validates quality thresholds to approve or reject the prompt modification.
Cost analysis: the tipping point
Let’s look at the numbers behind the argument.
Offline Evaluation Cost
Assume a CC/CD cycle that runs a complete evaluation on a dataset of 1,000 interactions for each prompt change (assuming ~2,000 input tokens and ~300 output tokens per evaluation).
Proprietary Model (Premium)
- Input Cost (per 1M): ~$5.00
- Output Cost (per 1M): ~$15.00
- Cost of 1,000 Evaluations: ~$14.50 per run
Qwen 3.x (Own Infrastructure)
- Input Cost (per 1M): Fixed (amortized)
- Output Cost (per 1M): Fixed (amortized)
- Cost of 1,000 Evaluations: Marginal (~$0)
For Offline, the savings are attractive but not decisive. But in Online, the story changes.
Online Evaluation Cost (Calibration in Production)
If you have an application that generates 1,000,000 traces per month, and you want to apply CC/CD by evaluating a representative sample:
10% trace sampling
- Volume Evaluated / Month: 100,000 evals
- Proprietary API Cost ($14.5/1K): ~$1,450 / month
- Own Infrastructure (Qwen): Fixed Server (~$1,000/month)
20% trace sampling
- Volume Evaluated / Month: 200,000 evals
- Proprietary API Cost ($14.5/1K): ~$2,900 / month
- Own Infrastructure (Qwen): Fixed Server (~$1,000/month)
30% trace sampling
- Volume Evaluated / Month: 300,000 evals
- Proprietary API Cost ($14.5/1K): ~$4,350 / month
- Own Infrastructure (Qwen): Fixed Server (~$1,000/month)
The tipping point is clear: as soon as you scale continuous monitoring in production, relying on proprietary APIs for LLM-as-a-Judge destroys your operational margins. Using an open-weights model gives you the freedom to evaluate aggressively Online without fear of the bill at the end of the month.
Conclusion
Maturity in AI engineering is not about writing the “perfect prompt.” It’s about building a system that allows you to objectively know when a prompt is better than the previous one. The CC/CD framework, powered by Langfuse Self-Hosted and Open-Weights models like Qwen 3.x as judges, enables precisely that.
Offline evaluations ensure you don’t break anything when deploying. Online evaluations guarantee you keep your finger on the pulse of reality in production. If you manage to integrate both, you’ll transform prompts from “magical text strings” into true software components that are controlled, calibrated, and improvable.
If you want to dive deeper into how this flow looks applied in a real business case, I recommend reading my guest article detailing the CC/CD framework. And if you’re looking to optimize your inference stack, check out my previous posts on the impact of using Open Weights models instead of proprietary APIs.
How are you evaluating your prompts in production today? CC/CD could be your next natural step.