LLM-as-a-Judge: como construir pipelines de avaliação de IA que escalonam

Os prompts em sistemas com Large Language Models (LLMs) não se comportam como código determinístico. Em um desenvolvimento de software tradicional, se você modifica uma função e todos os testes passam, você pode fazer deploy com confiança. Com os LLMs, uma mudança mínima no prompt para melhorar o tom de uma resposta pode, inadvertidamente, fazer com que o modelo pare de extrair uma entidade chave ou falhe ao invocar uma ferramenta externa (tool call).
Essa regressão silenciosa é o maior risco ao operar IA em produção. Sem um pipeline de avaliação sistemática, iterar prompts é essencialmente uma aposta. A avaliação manual não escala, e usar métricas de similaridade de texto tradicionais fica aquém. O padrão LLM-as-a-Judge resolve isso usando um modelo para avaliar outro.
Vou mostrar como construir um pipeline de avaliação que escale economicamente para ambientes de produção, baseado na minha experiência construindo esses sistemas em larga escala.
O framework CC/CD: Além do CI/CD clássico
Quando desenvolvemos software tradicional, usamos CI/CD (Continuous Integration / Continuous Deployment), onde o objetivo é construir, testar exaustivamente e chegar ao deploy como a meta final do ciclo. Mas para sistemas de IA generativa, essa abordagem linear fica aquém. O novo modelo é o CC/CD (Continuous Calibration / Continuous Development), onde o deploy não é o fim do processo, mas apenas uma transição para o verdadeiro fine-tuning.
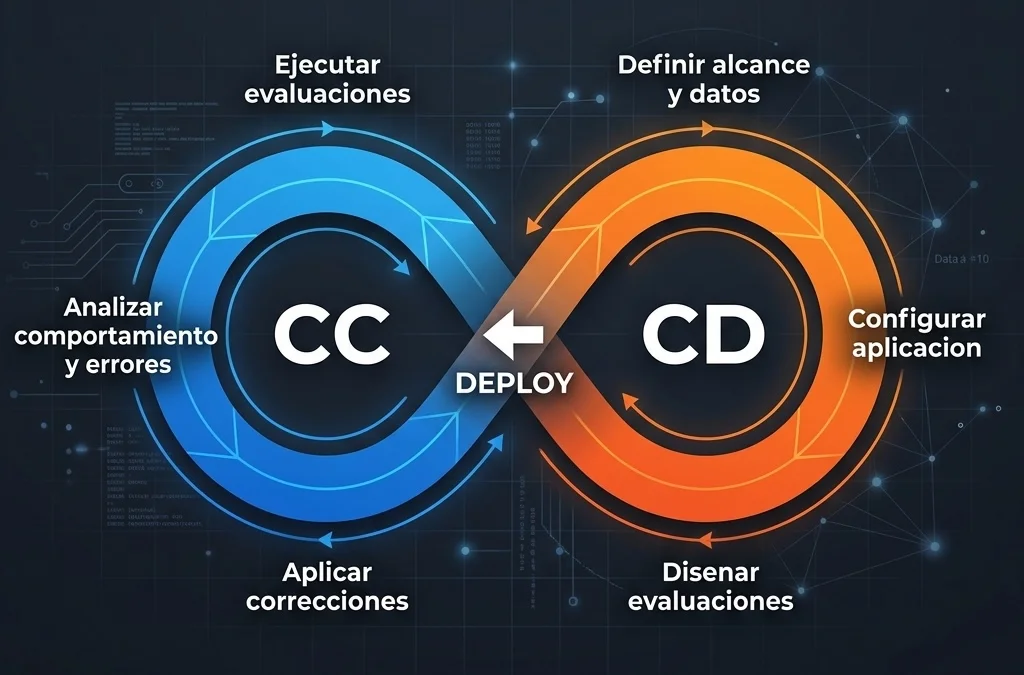
Fase de Continuous Development
- O ciclo começa ao estabelecer diferentes versões de um prompt focadas em um caso de uso particular.
- Um conjunto de dados base é coletado contendo interações representativas para validar como o sistema deveria responder.
- Métricas customizadas são configuradas e modelos são designados para atuar como juízes para pontuar os resultados.
Fase de Continuous Calibration
- Para qualquer ajuste em um prompt, uma validação automatizada é executada contra o conjunto de dados de controle (ground truth).
- Atributos-chave como aderência ao formato, tom e precisão das informações são quantificados usando LLMs avaliadores.
- Uma mudança só recebe luz verde para produção se superar as métricas de qualidade estabelecidas anteriormente.
- Uma vez ao vivo, o tráfego real é monitorado para identificar anomalias ou degradações sutis.
- O processo é cíclico. Erros detectados em produção alimentam de volta o ambiente de testes para refinar prompts e contextos gradualmente.
Calibração contínua significa que assumimos que o modelo nunca é perfeito desde o dia 1. Requer ajustes empíricos baseados em interações reais.
Avaliação Offline vs. Online
Para implementar CC/CD com sucesso, você precisa estruturar suas avaliações em duas frentes complementares:
Avaliação Offline
É sua rede de segurança antes de fazer deploy. Cada vez que você modifica um prompt ou troca de modelo, dispara uma avaliação sobre um dataset estático e curado (ground truth).
- Contexto / Quando usar Pré-deploy, usando um dataset controlado e histórico.
- Trigger Modificação de prompt, atualização de modelo ou mudança na lógica RAG.
- Propósito Detectar e prevenir regressões, e comparar versões base.
- Custo em Escala Baixo (volume fixo).
Avaliação Online
É seu radar em produção. Usa tráfego real para pontuar continuamente o desempenho do modelo em interações ao vivo.
- Contexto / Quando usar Pós-deploy, monitoramento em tempo real com tráfego ao vivo de usuários.
- Trigger Trazas geradas por interações do usuário em produção (sampling).
- Propósito Detectar degradação progressiva, monitorar a saúde e alimentar o dataset Offline com novos edge cases.
- Custo em Escala Alto (escala com o tráfego real).
O argumento econômico para modelos Open-Weights em avaliação
No meu post anterior sobre reduzindo custos de LLMs com modelos Open Weights e Qwen 3.5 na AWS, mencionei que a avaliação automatizada é o caso de uso perfeito para modelos deployados em infraestrutura própria.
Por quê? Porque embora a avaliação Offline possa ser custosa usando APIs proprietárias (ex. OpenAI, Anthropic), a verdadeira quebra econômica acontece na avaliação Online.
Se você quer avaliar 20% ou 30% das suas trazas em produção para ter uma amostra estatisticamente significativa da qualidade das suas respostas, o custo de usar um modelo proprietário para pontuar cada interação dispara e pode superar o custo da inferência principal da sua aplicação. Os modelos open-weights (como a família Qwen 3.5 ou 3.6 deployada na AWS) não são apenas uma otimização de custos. São uma alternativa financeiramente viável para escalar a calibração Online.
O stack: Langfuse Self-Hosted e Juízes Customizados
A peça central da nossa arquitetura de avaliação é o Langfuse. Embora o Langfuse Cloud seja uma excelente porta de entrada para equipes pequenas, para ambientes de produção maduros recomendo Langfuse Self-Hosted em sua própria infraestrutura (ex. em Kubernetes corporativo ou AWS ECS).
Por quê Self-Hosted?
- Soberania de Dados Os prompts e respostas em produção frequentemente contêm informações sensíveis dos clientes que não devem ser enviadas para plataformas de observabilidade SaaS de terceiros.
- Custos Previsíveis Um cluster com capacidade fixa para Langfuse custa uma fração comparado com os tiers baseados em volume em nível empresarial.
- Validação em Produção É o mesmo padrão que operei com sucesso em produção em larga escala.
O Langfuse gerencia o versionamento de prompts, a gestão de datasets e o registro de trazas e scores.
Juízes Pré-configurados vs. Juízes Customizados
O Langfuse oferece avaliadores pré-configurados (ex. toxicidade, sentimento), que são um ótimo ponto de partida. Mas para que o padrão LLM-as-a-Judge seja verdadeiramente efetivo, você precisa construir juízes customizados.
Um juiz customizado deve conter:
- Um prompt template altamente específico para o seu caso de uso.
- Uma rúbrica clara de pontuação (ex. de 0 a 1).
- Exemplos few-shot do domínio de negócio (ex. o que um 0.2 vs um 0.9 significa no seu contexto específico).
Taxonomia de LLM-as-a-Judge, Métricas e Vieses
Variantes do Juiz
- Single Judge Um único modelo avalia uma resposta baseada em uma rúbrica. (Mais rápido e econômico).
- Pairwise Comparison O modelo recebe duas respostas (A e B) e escolhe a melhor. (Melhor para A/B testing).
- Reference-Based (Ground Truth) O modelo compara a resposta gerada com uma resposta ideal de referência.
Métricas-Chave
Você pode projetar seus próprios prompts de avaliação para métricas como:
- Relevância A saída responde à pergunta do usuário sem divagar?
- Coerência A resposta é logicamente sólida do início ao fim?
- Faithfulness (Fidelidade em RAG) A resposta se baseia estritamente no contexto fornecido ou alucina informações?
- Tom/Estilo A resposta mantém a voz definida da marca corporativa?
- Aderência ao Formato O modelo respeitou o formato solicitado (ex. JSON estrito sem preâmbulos)?
Template de prompt de exemplo para Faithfulness (Single Judge):
Você é um avaliador especialista. Analise se a RESPOSTA se baseia unicamente no CONTEXTO fornecido.
Não avalie se a resposta está correta no mundo real, apenas se é inferida diretamente do contexto.
[CONTEXTO]
[RESPOSTA]
Avalie em uma escala de 0.0 (totalmente alucinado ou não relacionado) a 1.0 (perfeitamente fiel ao contexto).
Retorne sua avaliação em formato JSON: {"score": 0.x, "reasoning": "sua justificativa breve"}
Um score baixo em Faithfulness indica alto risco de alucinação e a necessidade imediata de ajustar o prompt do sistema RAG.
Vieses do Juiz e Mitigação
LLMs como juízes não são perfeitos e introduzem seus próprios vieses:
- Position Bias Em comparações pairwise, o modelo tende a favorecer a resposta apresentada primeiro. Mitigação Randomizar a ordem de A e B e promediar.
- Verbosity Bias O modelo assume que uma resposta mais longa é “melhor”, mesmo que inclua preenchimento. Mitigação Adicionar instruções explícitas na rúbrica penalizando a verbosidade excessiva.
- Self-Enhancement Bias Se você usa Llama 3 para avaliar Llama 3, ele tenderá a dar pontuações mais altas a si mesmo. Mitigação Usar um modelo juiz de uma família diferente ao avaliado (ex. avaliar saídas da OpenAI usando Qwen).
Checklist de Verificação de Vieses
- A ordem das opções nas avaliações Pairwise é randomizada.
- A rúbrica penaliza explicitamente respostas longas e desnecessárias (Verbosity Bias).
- O modelo juiz pertence a uma família ou versão diferente do modelo gerador.
- O juiz retorna uma justificativa ou raciocínio (Chain-of-Thought) antes do score numérico.
Implementação com Qwen 3.x e Langfuse SDK
Para o modelo juiz local, recomendo a família Qwen 3.x pela sua excelente relação qualidade-preço e capacidades multilíngues.
Qwen 3.5 ou 3.6?
- Escolha Qwen 3.5 (72B ou 32B) se você vai avaliar altos volumes de trazas Online e precisa de um equilíbrio ótimo entre desempenho (TPS) e orçamento de infraestrutura.
- Escolha Qwen 3.6 se você está avaliando domínios muito técnicos, raciocínio complexo ou matemática, onde precisa da maior precisão possível sem importar uma leve penalização no custo de computação.
Em vez de construir scripts complexos e isolados, a melhor prática é orquestrar esse processo com pipelines no Jenkins (ou sua ferramenta de CI/CD). Você pode configurar um pipeline que dispare ante qualquer modificação de um prompt e execute um script de avaliação que faça o seguinte:
- Recupera o prompt modificado do Langfuse.
- Recupera o dataset controlado de testes do Langfuse.
- Executa o prompt contra os dados no dataset de testes.
- Gera as trazas das execuções no Langfuse associando-as a uma tag ou label em particular.
- Registra os experimentos no Langfuse, vinculando as trazas geradas previamente.
- Executa a avaliação: o Langfuse executa os LLM-as-a-Judge contra o ambiente e as tags das execuções (avaliação Online controlada).
- Valida limiares de qualidade para aprovar ou rejeitar a modificação do prompt.
Análise de custos: o ponto de inflexão
Vejamos os números por trás do argumento.
Custo de Avaliação Offline
Suponhamos um ciclo de CC/CD que executa uma avaliação completa sobre um dataset de 1.000 interações para cada mudança no prompt (assumindo ~2.000 tokens de input e ~300 de output por avaliação).
Modelo Proprietário (Premium)
- Custo Input (por 1M): ~$5.00
- Custo Output (por 1M): ~$15.00
- Custo de 1.000 Avaliações: ~$14.50 por run
Qwen 3.x (Infraestrutura própria)
- Custo Input (por 1M): Fixo (amortizado)
- Custo Output (por 1M): Fixo (amortizado)
- Custo de 1.000 Avaliações: Marginal (~$0)
Para Offline, a economia é atraente mas não determinante. Mas na Online a história muda.
Custo de Avaliação Online (Calibração em Produção)
Se você tem uma aplicação que gera 1.000.000 de trazas por mês e quer aplicar CC/CD avaliando uma amostra representativa:
Amostragem de 10% das trazas
- Volume Avaliado / Mês: 100.000 evals
- Custo API Proprietária ($14.5/1K): ~$1.450 / mês
- Custo Infra Própria (Qwen): Servidor Fixo (~$1.000/mês)
Amostragem de 20% das trazas
- Volume Avaliado / Mês: 200.000 evals
- Custo API Proprietária ($14.5/1K): ~$2.900 / mês
- Custo Infra Própria (Qwen): Servidor Fixo (~$1.000/mês)
Amostragem de 30% das trazas
- Volume Avaliado / Mês: 300.000 evals
- Custo API Proprietária ($14.5/1K): ~$4.350 / mês
- Custo Infra Própria (Qwen): Servidor Fixo (~$1.000/mês)
O ponto de inflexão é claro: tão logo você escale o monitoramento contínuo em produção, depender de APIs proprietárias para LLM-as-a-Judge destrói suas margens operacionais. Usar um modelo open-weights te dá a liberdade de avaliar agressivamente em Online sem medo da factura no final do mês.
Conclusão
A maturidade na engenharia de IA não se trata de escrever o “prompt perfeito”. Trata-se de construir um sistema que permita saber objetivamente quando um prompt é melhor que o anterior. O framework CC/CD, impulsionado pelo Langfuse Self-Hosted e modelos Open-Weights como Qwen 3.x como juízes, permite precisamente isso.
As avaliações Offline garantem que você não quebre nada ao fazer deploy. As avaliações Online garantem que você mantenha o pulso da realidade em produção. Se você conseguir integrar ambas, transformará os prompts de “strings de texto mágicas” em verdadeiros componentes de software controlados, calibrados e melhoráveis.
Se você quer se aprofundar em como esse fluxo é aplicado em um caso de negócio real, recomendo ler meu artigo convidado detalhando o framework CC/CD. E se você está buscando otimizar seu stack de inferência, confira meus posts anteriores sobre o impacto de usar modelos Open Weights em vez de APIs proprietárias.
Como você está avaliando seus prompts em produção hoje? O CC/CD pode ser o seu próximo passo natural.