Reducing LLM Costs by Up to 90% with Open-Weights Models

Lately there’s a lot of talk about “free” LLMs, heavily promoted by tech influencers. But are they really free? You have to read the fine print of the usage policies, which are often confusing. The vast majority of these models use your data to feed their training, which rules them out for enterprise, high-security, or production environments. For truly free models with production-ready capabilities and full security, I recommend open-weights models with Apache licenses and self-hosting.
After weeks of benchmarking with open-weights models for critical tasks (such as RAG and Tool Calling), the results speak for themselves: models like Qwen 3.5 (Alibaba) or Gemma 4 (Google) already have the capability to displace GPT-4 or even GPT-5.2 in massive production workflows, reducing operational costs by up to 90%.
I thoroughly tested RAG, tool calling, code generation, and more scenarios. Running locally, Qwen3.5 9B (without advanced reasoning) passed all tests without issues. And an important detail: it’s not even the most powerful version in the Qwen 3.5 family; above it are the 27B, 35B, 122B, and 397B models for Cloud.
The evolution of open-weights in recent months has been massive. Thanks to the work of Alibaba, Meta, and Google, the developer community has managed to create quantized versions that run on devices with limited memory. This is pulling innovation out of the monopoly of big tech companies.
Ideal Use Cases
One of the most cost-effective uses for these local models is background automation:
- CI/CD Pipelines: Code analysis and deployment automation.
- Prompt Training with CC/CD: Automated AI behavior testing.
- LLM-as-a-Judge Evaluation: Using a local model to validate the quality of other models’ responses.
- Batch Data Processing: Long-running tasks where speed isn’t the issue, but token volume is extremely high.
- Massive Data Optimization and Cleanup: Structuring tons of unstructured text.
Until recently, processing all of this at scale was unthinkable due to how expensive commercial APIs are. Today, a local model perfectly covers the basics: RAG, tool usage, and agent orchestration.
Key Features of Open-Weights Models
- Portability: The model file can be downloaded and run on private servers, own clouds, or even local hardware if sufficient power is available.
- Fine-tuning: With access to the weights, developers can perform additional training with specific data to specialize the model for a particular task or domain.
- Privacy and Control: Since the model doesn’t reside on a third party’s servers, processed data never leaves the user’s infrastructure, which is critical for companies with strict security regulations.
- Limited Transparency: Although the weights can be viewed, the exact data used for training or the specific filtering algorithms are often unknown, so they don’t always meet the Open Source Initiative’s (OSI) strict definition of “Open Source.”
How to Run Models Locally
Setting up these models via API locally is very easy using Ollama (or your preferred inference engine).
To install Ollama on Mac or Linux, simply run this in the terminal:
curl -fsSL https://ollama.com/install.sh | sh
Start the server:
ollama serve
And pull the model:
ollama pull <model_name>
You can control model behavior via the API, but sometimes you need to lock in fixed parameters. This is key if you’re going to connect it to tools like OpenCode, Copilot, or Claude Code, since these assistants require the model to be configured from the start; it’s not possible to customize their parameters (like context window or temperature) directly from their chat or editor settings. To create a ready-to-use custom version:
# Run the model
ollama run <model_name>
# Set the context window
/set parameter num_ctx 65536
# Set the initial temperature
/set parameter temperature 0.3
# Save the model with a custom name
/save qwen3.5:9b-64k
# Exit the model
/bye
List of parameters available in Ollama.
Some Tests Performed
1. Tool Detection and Invocation (Tool Calling)
I set up an example using a fictitious tool (consultar_bd_libreria) to see how well the model understood user intent and passed the correct parameters to the tool.
Quick verdict: Qwen 3.5 9B solved everything on the first try. The smaller version (4B) worked for simple queries, but started hallucinating with complex requirements when the system prompt wasn’t strict enough.
Query about “love books by Gabriel García Márquez” with the qwen3.5:9b model with a 64,000 token window:
curl -X POST \
'http://localhost:11434/api/chat' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "qwen3.5:9b-64k",
"messages": [
{
"role": "system",
"content": "You are a virtual assistant for a bookstore responsible for providing information about the catalog of available books and authors."
},
{
"role": "user",
"content": "Hello! Good morning. Hey, by any chance would you have any book by Gabriel García Márquez that's about love?"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "consultar_bd_libreria",
"description": "Searches the bookstore database for information about authors and books.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The optimized user query: without greetings, grammatically corrected, and focused exclusively on search criteria (e.g., '\''love books by Gabriel García Márquez'\'')."
}
},
"required": ["query"]
}
}
}
],
"think": false,
"stream": false
}'
Response (Qwen 3.5 9B):
{
"model": "qwen3.5:9b-64k",
"created_at": "2026-04-13T05:04:18.274354Z",
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "call_y9mljhip",
"function": {
"index": 0,
"name": "consultar_bd_libreria",
"arguments": {
"query": "love books by Gabriel García Márquez"
}
}
}
]
},
"done": true,
"done_reason": "stop",
"total_duration": 7161121041,
"load_duration": 186818208,
"prompt_eval_count": 382,
"prompt_eval_duration": 4331394542,
"eval_count": 38,
"eval_duration": 2460080082
}
Complex query with the qwen3.5:9b model with a 64,000 token window:
curl -X POST \
'http://localhost:11434/api/chat' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "qwen3.5:9b-64k",
"messages": [
{
"role": "system",
"content": "You are a virtual assistant for a bookstore responsible for providing information about the catalog of available books and authors."
},
{
"role": "user",
"content": "Hi! How's everything going? Look, I'm looking for something by Isabel Allende or maybe Gabriel García Márquez, but it has to be magical realism and shouldn't cost me more than 25 dollars, okay? Oh, and only if you have it in the store so I can pick it up today, it's for a gift."
}
],
"tools": [
{
"type": "function",
"function": {
"name": "consultar_bd_libreria",
"description": "Searches the bookstore database for information about authors and books.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The optimized user query: without greetings, grammatically corrected, and focused exclusively on search criteria (e.g., '\''love books by Gabriel García Márquez'\'')."
}
},
"required": ["query"]
}
}
}
],
"think": false,
"stream": false
}'
Response (Qwen 3.5 9B):
{
"model": "qwen3.5:9b-64k",
"created_at": "2026-04-13T04:59:53.121743Z",
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "call_fqw4hdq7",
"function": {
"index": 0,
"name": "consultar_bd_libreria",
"arguments": {
"query": "magical realism books by Isabel Allende or Gabriel García Márquez with price under 25 dollars available in store"
}
}
}
]
},
"done": true,
"done_reason": "stop",
"total_duration": 15120528125,
"load_duration": 8777821167,
"prompt_eval_count": 431,
"prompt_eval_duration": 2368185708,
"eval_count": 57,
"eval_duration": 3715160875
}
We can see that with a smaller model like qwen3.5:4b, a simple instruction has no problems:
{
"model": "qwen3.5:4b-64k",
"created_at": "2026-04-13T05:37:48.126052Z",
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "call_emre4xhh",
"function": {
"index": 0,
"name": "consultar_bd_libreria",
"arguments": {
"query": "love books by Gabriel García Márquez"
}
}
}
]
},
"done": true,
"done_reason": "stop",
"total_duration": 8853187542,
"load_duration": 5582010334,
"prompt_eval_count": 382,
"prompt_eval_duration": 1257315083,
"eval_count": 38,
"eval_duration": 1791458750
}
But for a complex query, the qwen3.5:4b model can no longer be efficient, easily hallucinating without a more robust system prompt. Faced with the same complex text, the 4B one got confused, ignored the tool, and started chatting:
{
"model": "qwen3.5:4b-64k",
"created_at": "2026-04-13T05:38:48.359164Z",
"message": {
"role": "assistant",
"content": "Hello! Everything's great here, thanks for asking. I'm glad you're looking for a gift; magical realism is a fascinating genre.\n\nTo help you find exactly what they have in stock today in the store and that fits your 25 dollar budget, I need you to give me a little help with the search.\n\nPlease tell me: **Would you prefer I search first for books by Isabel Allende or by Gabriel García Márquez?** (Or if you have a specific title in mind, you can tell me that too)."
},
"done": true,
"done_reason": "stop",
"total_duration": 11457394291,
"load_duration": 4015661708,
"prompt_eval_count": 431,
"prompt_eval_duration": 1329063875,
"eval_count": 121,
"eval_duration": 5790543085
}
2. RAG Extraction with Reasoning, Math, and Tone
I fed it a text with the rules of “EcoMóvil,” a fictitious scooter company. I asked it to calculate the cost of a trip, resolve a breakdown, and asked about a piece of data that simply didn’t exist in the document. All of this with a strict system rule: friendly tone, zero emojis.
curl -X POST \
'http://localhost:11434/api/chat' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "qwen3.5:9b-64k",
"messages": [
{
"role": "system",
"content": "You are '\''EcoBot'\'', the virtual customer service assistant for '\''EcoMóvil'\'', an electric scooter rental company. Your tone should be friendly, enthusiastic, ecological, and very professional. STRICT INSTRUCTION: You are absolutely prohibited from using emojis, emoticons, or similar graphic characters in your responses. Maintain a clean text format. Your task is to answer user questions based EXCLUSIVELY on the provided context. If the answer is not found in the text, politely apologize and explain that you don't have that information at hand, without making up data.\n\n<retrieved_context>\n[ARTICULO_SOPORTE: TARIFAS_Y_USO_2026]\n- Rates: Unlocking a scooter costs $1.00 USD. The cost per minute of use is $0.25 USD.\n- Hours: The service operates every day from 06:00 AM to 11:00 PM. Scooters are automatically locked and cannot be started outside these hours.\n- Allowed zones: Scooters can only circulate and be parked within the '\''Centro Metropolitano Area'\'' and the '\''University Campus'\''. Parking outside these zones carries an automatic fine of $25.00 USD on the associated card.\n- Breakdowns: If a scooter has mechanical failures during the trip, the user must end the trip immediately in the app to stop the charge and press the '\''Report Problem'\'' button to notify the technical team.\n</retrieved_context>"
},
{
"role": "user",
"content": "Hello! I wanted to know exactly how much a 20-minute trip would cost me. Also, what happens if the scooter gets a flat tire halfway? And, are they planning to expand the service to the north side of the city next month?"
}
],
"think": false,
"stream": false
}'
Qwen 3.5 9B: Precise and natural response. Respected the no-emoji rule, admitted not knowing the answer about the made-up data, and the math calculation ($1.00 unlock + (20 min * $0.25) = $6.00) was exact.
{
"model": "qwen3.5:9b-64k",
"created_at": "2026-04-13T06:06:54.100627Z",
"message": {
"role": "assistant",
"content": "Hello! It's a pleasure to greet you. At EcoMóvil we love that you want to know more about our services.\n\nTo calculate the cost of a 20-minute trip, you first need to consider that unlocking the scooter costs $1.00 USD. Then, the cost per minute of use is $0.25 USD. Therefore, the 20-minute trip would have a usage cost of $5.00 USD (20 minutes multiplied by $0.25). Adding the unlock cost, the total to pay would be $6.00 USD.\n\nRegarding the situation of a flat tire, if the scooter has mechanical failures during the trip, it's essential that you end the trip immediately in the application to stop the charge. Afterwards, you must press the 'Report Problem' button within the app to notify the technical team so they can assist you.\n\nLastly, regarding the expansion of the service to the north side of the city, unfortunately I don't have that information at hand right now. I recommend checking our social media or the news section in our application to stay up to date on future expansion plans.\n\nIs there anything else I can help you with today?"
},
"done": true,
"done_reason": "stop",
"total_duration": 28816119625,
"load_duration": 8543402584,
"prompt_eval_count": 442,
"prompt_eval_duration": 2152467708,
"eval_count": 272,
"eval_duration": 17493256088
}
Qwen 3.5 4B: Maintained the customer service tone well, but messed up the math logic in several of the exercises I threw at it afterwards.
{
"model": "qwen3.5:4b-64k",
"created_at": "2026-04-13T05:48:37.869663Z",
"message": {
"role": "assistant",
"content": "Hello! It's a pleasure to greet you. As an EcoMóvil assistant, I'm here to help you plan your trip efficiently and responsibly.\n\nTo calculate the cost of your 20-minute trip, we need to consider the base unlock cost and the per-minute rate. The initial cost to unlock a scooter is 1.00 USD. Additionally, the usage rate is 0.25 USD per minute. Multiplying 20 minutes by 0.25 USD, we get a cost of 5.00 USD for the usage time. Adding the unlock cost, the total price for a 20-minute trip would be 6.00 USD.\n\nRegarding your question about breakdowns, if a scooter has mechanical failures during the trip, it's essential that you end the trip immediately through the application to stop any additional charges. Afterwards, you must press the 'Report Problem' button in the app to notify the technical team, who will handle the repair.\n\nRegarding the expansion of the service to the north side of the city, unfortunately I don't have that information available in my current records. My database is limited to current rates, schedules, and allowed zones, which are the Centro Metropolitano Area and the University Campus. Parking outside these zones carries an automatic fine of 25.00 USD, so I recommend checking official routes to avoid fines.\n\nI'm available if you need more information about our services or have any other questions. I hope you have a safe and ecological trip!"
},
"done": true,
"done_reason": "stop",
"total_duration": 25273808667,
"load_duration": 5406114208,
"prompt_eval_count": 442,
"prompt_eval_duration": 1319714917,
"eval_count": 359,
"eval_duration": 17672467651
}
Qwen 3.5 2B: Grammatically fine, but got basic calculations wrong and offered responses that were too brief, abruptly cutting off the conversation.
{
"model": "qwen3.5:2b-64k",
"created_at": "2026-04-13T05:58:35.337881Z",
"message": {
"role": "assistant",
"content": "Hello! Of course, I'm here to help you plan your trip with EcoMóvil.\n\nA 20-minute trip will cost exactly $5.00 USD, calculated as $0.25 USD per minute multiplied by 20 minutes.\n\nIf the scooter gets a flat tire halfway, we recommend ending the trip immediately in the application to stop the charge and pressing the \"Report Problem\" button to notify the technical team.\n\nRegarding zone expansion, the service currently operates within the Centro Metropolitano Area and the University Campus. I don't have information available about specific plans to expand the service to the north side of the city next month, but I recommend checking directly with our support team or visiting our website for the most up-to-date information.\n\nI hope this information is useful for your next adventure in EcoMóvil. Have a great day!"
},
"done": true,
"done_reason": "stop",
"total_duration": 11193157167,
"load_duration": 4680604292,
"prompt_eval_count": 442,
"prompt_eval_duration": 535022292,
"eval_count": 205,
"eval_duration": 5662032366
}
When we change the system prompt for slightly more complex but still simple calculation logic, only the qwen3.5:9b model manages to pass with precision.
qwen3.5:9b:
{
"model": "qwen3.5:9b-64k",
"created_at": "2026-04-13T06:27:43.570695Z",
"message": {
"role": "assistant",
"content": "Hello. To calculate the total cost of your 10-minute trip in the Centro Area, we will apply the following concepts:\n\n1. **Unlock cost:** Since the trip duration is 10 minutes (less than 15 minutes), an unlock fee of $2.00 USD applies.\n2. **Per-minute rate:** $0.25 USD per minute is charged. For 10 minutes, the cost is $2.50 USD.\n3. **Zone fine:** The trip is within the Centro Area, so no fine applies.\n\n**Final calculation:**\n$2.00 (unlock) + $2.50 (per-minute rate) = $4.50 USD.\n\nThe total cost of your trip will be **$4.50 USD**."
},
"done": true,
"done_reason": "stop",
"total_duration": 22793113666,
"load_duration": 8255305416,
"prompt_eval_count": 186,
"prompt_eval_duration": 1053119459,
"eval_count": 197,
"eval_duration": 12840003246
}
qwen3.5:4b:
{
"model": "qwen3.5:4b-64k",
"created_at": "2026-04-13T06:26:00.84569Z",
"message": {
"role": "assistant",
"content": "Hello. To calculate the total cost of your 10-minute trip within the Centro Zone, we first need to determine the unlock cost.\n\nSince your trip lasts 10 minutes, which is less than 15 minutes, the unlock is not free and is calculated at the rate of $0.25 USD per minute. The unlock cost is $2.50 USD (10 minutes x $0.25).\n\nAssuming there are no other additional charges like fines for leaving the zone, the total trip cost is $2.50 USD."
},
"done": true,
"done_reason": "stop",
"total_duration": 9396311125,
"load_duration": 480919291,
"prompt_eval_count": 186,
"prompt_eval_duration": 779439167,
"eval_count": 135,
"eval_duration": 6620469968
}
qwen3.5:2b:
{
"model": "qwen3.5:2b-64k",
"created_at": "2026-04-13T06:22:52.715915Z",
"message": {
"role": "assistant",
"content": "Hello. To take a 10-minute trip within the Centro area, the unlock fee is $2.00 USD."
},
"done": true,
"done_reason": "stop",
"total_duration": 5984044125,
"load_duration": 4802225125,
"prompt_eval_count": 186,
"prompt_eval_duration": 290848333,
"eval_count": 31,
"eval_duration": 796598664
}
3. As a Development Assistant
I connected it to OpenCode, Copilot, and Claude Code. The 9B version works well for autocompletion and refactoring locally. If you’re going to build complex architectures, you’ll need the larger models, and there you absolutely need a Cloud server or a fairly robust local machine (like a Mac Mini with 32GB or 64GB of RAM).
Qwen3.5 Benchmarks
In the official benchmark we can see its full power compared to other models:
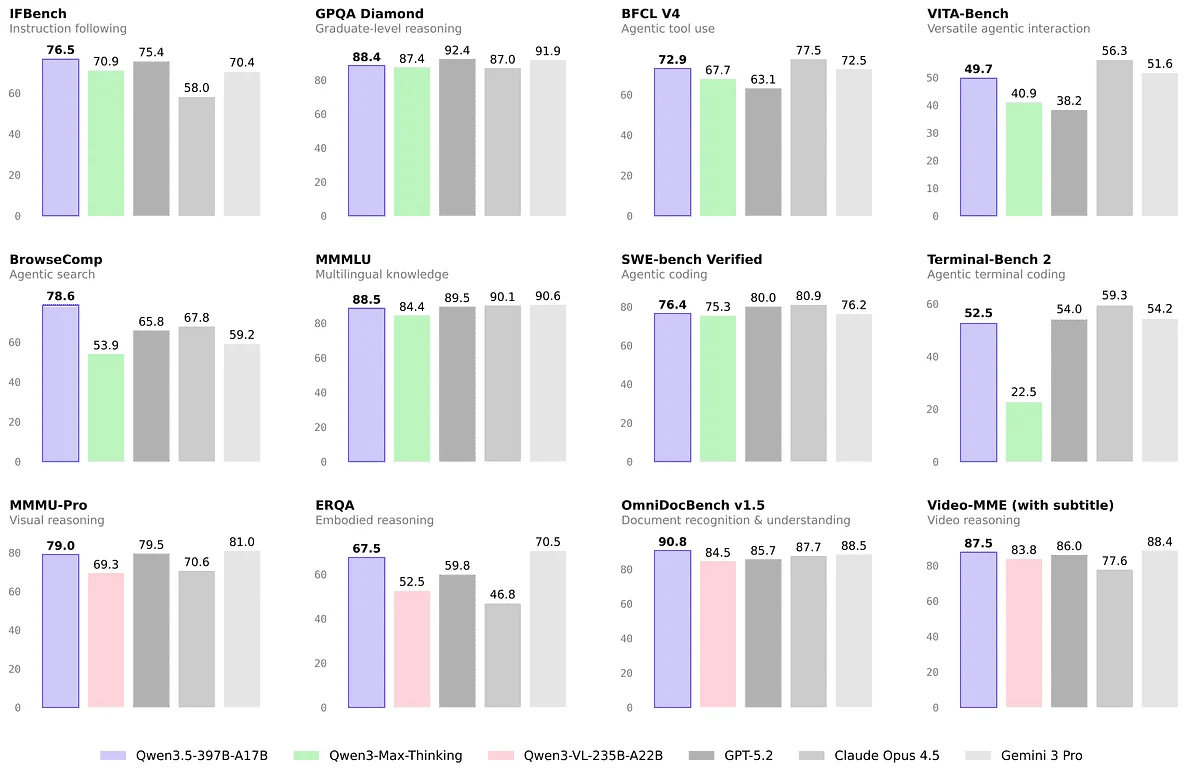
If we look at the official numbers against commercial models, the performance vs. price difference is massive:
The real leap of Qwen 3.5 is in its use as an autonomous agent. In the BrowseComp benchmark (automated web search and navigation), it reaches 78.6 points. It significantly surpasses Gemini 3 Pro (59.2) and is hot on the heels of Claude 4.5 Opus (84.0).
When orchestrating APIs or processing external data, Qwen 3.5 competes head-to-head with much more expensive paid models. It’s proof that today a company can stop depending exclusively on external providers for its AI core.
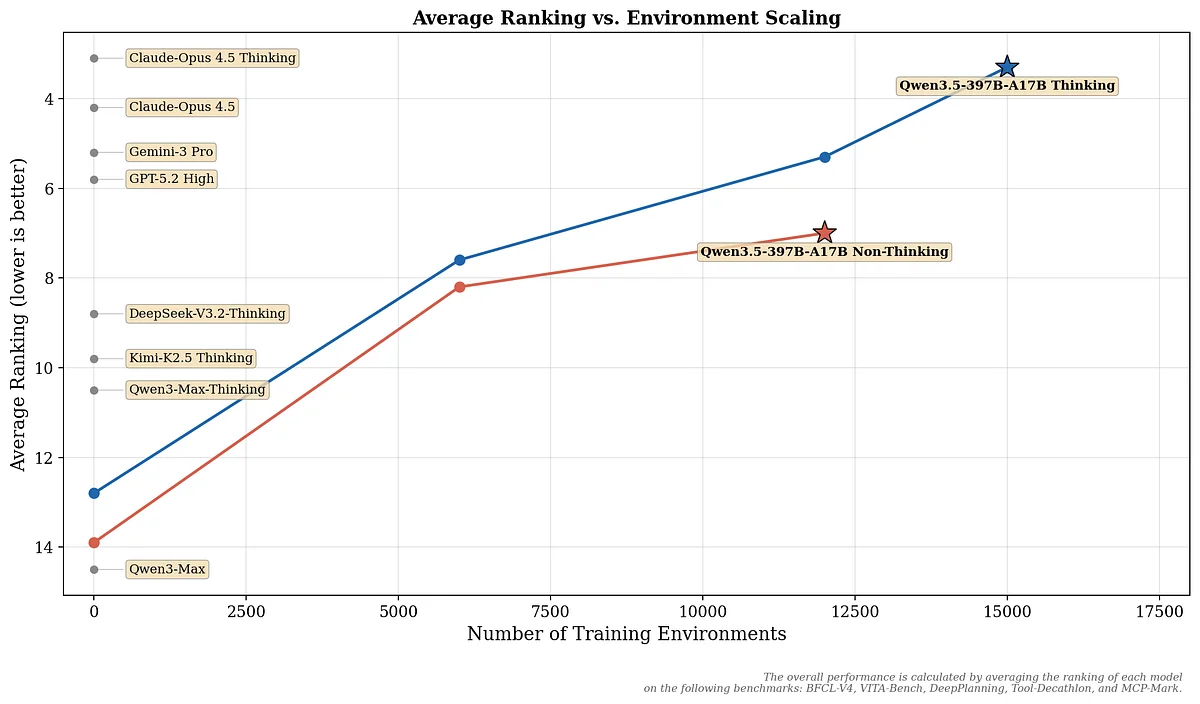
When Is It Worth Going for Open-Weights Models?
- Massive token usage: If your product burns millions of tokens per month, the API bill is going to hurt. You need to do the math right (servers vs. API), but hosting a model like
qwen3.5can lower the monthly bill by more than 90%. - Strict privacy rules: If you work with medical data, PII, or financial data, your VPC is your refuge. Running everything locally guarantees that data never touches a third-party server.
- Custom tailoring: When you need to do fine-tuning so the model speaks the technical language of your industry without having to train a foundational model from scratch.
Conclusion
The reality is that for 80% of LLM operations in production (classifying texts, RAG, tool calling), you don’t need to pay for the smartest model on the market.
You can delegate a large part of the workload to open-weights models hosted by you, especially for background tasks. The ideal architecture today is to have a good router: you use fast, cheap local models for simple tasks, and only call the giant commercial models when complex reasoning demands it.
My recommendation is that before making this change, make sure you have good observability, solid test datasets, and proper prompt management (with tools like Langfuse). This is where open-weights models also shine, allowing you to invoke thousands of LLM-as-a-Judge calls without impacting costs, increasing evaluated traces, and improving metrics in online evaluations.
And you, are you already moving your workloads to local models or still depending 100% on third-party APIs?