Reduciendo hasta un 90% los costos de LLMs con modelos Open-Weights

Últimamente se habla mucho de los LLM “gratuitos”, muy promocionados por influencers de tecnología. Pero, ¿son realmente gratuitos? Hay que leer la letra chica de las políticas de uso, que suelen ser confusas. La gran mayoría de estos modelos utilizan tus datos para retroalimentar su entrenamiento, lo que descarta su uso en entornos empresariales, de alta seguridad o productivos. Para modelos gratuitos realmente con posibilidad de uso en producción y total seguridad, recomiendo los modelos open-weights con licencia Apache y self-hosting.
Tras semanas de benchmarking con modelos open-weights para tareas críticas (como RAG y Tool Calling), los resultados hablan por sí solos: modelos como Qwen 3.5 (Alibaba) o Gemma 4 (Google) ya tienen la capacidad de desplazar a GPT-4 o hasta GTP-5.2 en flujos productivos masivos, bajando los costos operativos hasta en un 90%.
Probé a fondo escenarios de RAG, tool calling, generación de código, entre otros. Corriendo en local, Qwen3.5 9B (sin razonamiento avanzado) superó todas las pruebas sin problemas. Y un detalle importante: ni siquiera es la versión más potente de la familia Qwen 3.5; por encima están los modelos de 27B, 35B, 122B y 397B para Cloud.
La evolución de los open-weights en los últimos meses fue brutal. Gracias al trabajo de Alibaba, Meta y Google, la comunidad de desarrolladores logró crear versiones cuantizadas que corren en dispositivos con poca memoria. Esto está sacando la innovación del monopolio de las grandes big tech.
Casos de Uso Ideales
Uno de los usos más rentables para estos modelos locales está en la automatización en background:
- Pipelines de CI/CD: Análisis de código y automatización de despliegues.
- Entrenamiento de prompts con CC/CD: Pruebas automatizadas de comportamiento de la IA.
- Evaluación con LLM-as-a-judge: Usar un modelo local para validar la calidad de las respuestas de otros modelos.
- Procesamiento de datos en procesos batch: Tareas de largo aliento donde la velocidad no es el problema, pero el volumen de tokens es altísimo.
- Optimización y limpieza de datos masivos: Estructurar toneladas de texto suelto.
Hasta hace poco, era impensado procesar todo esto de forma masiva por lo caras que son las APIs comerciales. Hoy, un modelo local cubre perfectamente lo básico: RAG, uso de tools y orquestación de agentes.
Características principales de los modelos Open-Weights
- Portabilidad: El archivo del modelo se puede descargar y ejecutar en servidores privados, nubes propias o incluso hardware local si se cuenta con la potencia necesaria.
- Ajuste Fino (Fine-tuning): Al tener acceso a los pesos, los desarrolladores pueden realizar entrenamientos adicionales con datos específicos para especializar el modelo en una tarea o dominio particular.
- Privacidad y Control: Como el modelo no reside en los servidores de un tercero, los datos procesados no salen de la infraestructura del usuario, lo que es crítico para empresas con normativas de seguridad estrictas.
- Transparencia Limitada: Aunque se pueden ver los pesos, a menudo no se conoce con exactitud qué datos se utilizaron para entrenarlo o los algoritmos específicos de filtrado, por lo que no siempre cumplen con la definición estricta de “Open Source” de la Open Source Initiative (OSI).
Cómo ejecutar los modelos localmente
Levantar estos modelos vía API en local es muy fácil usando Ollama (o el motor de inferencia que prefieras).
Para instalar Ollama en Mac o Linux, simplemente tira esto en la terminal:
curl -fsSL https://ollama.com/install.sh | sh
Inicia el servidor:
ollama serve
Y baja el modelo:
ollama pull <nombre_del_modelo>
Puedes controlar cómo se comporta el modelo desde la API, pero a veces necesitas dejar parámetros fijos. Esto es clave si lo vas a enchufar a herramientas como OpenCode, Copilot o Claude Code, ya que estos asistentes requieren que el modelo esté configurado desde el principio; no es posible personalizar sus parámetros (como la ventana de contexto o la temperatura) directamente desde las configuraciones de su chat o editor. Para armar una versión personalizada lista para usar:
# Ejecutar el modelo
ollama run <nombre_del_modelo>
# Definir la ventana de contexto
/set parameter num_ctx 65536
# Definir la temperatura inicial
/set parameter temperature 0.3
# Guardar el modelo con un nombre personalizado
/save qwen3.5:9b-64k
# Salir del modelo
/bye
Lista de parámetros disponibles en ollama.
Algunas pruebas realizadas
1. Detección e Invocación de Tools (Tool Calling)
Armé un ejemplo usando una tool ficticia (consultar_bd_libreria) para ver qué tan bien el modelo entendía la intención del usuario y le pasaba los parámetros correctos al tool.
Veredicto rápido: Qwen 3.5 9B resolvió todo a la primera. La versión más chica (4B) sirvió para consultas simples, pero empezó a alucinar con requerimientos complejos cuando el system prompt no era lo suficientemente estricto.
Consulta sobre “libros de amor de Gabriel García Márquez” con el modelo qwen3.5:9b con ventana de 64.000 tokens:
curl -X POST \
'http://localhost:11434/api/chat' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "qwen3.5:9b-64k",
"messages": [
{
"role": "system",
"content": "Eres un asistente virtual de una librería encargado de facilitar información sobre el catálogo de libros y autores disponibles."
},
{
"role": "user",
"content": "¡Hola! Muy buenos días. Oye, ¿de casualidad tendrías algun libro de Gabriel García Marquéz que sea de amor?"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "consultar_bd_libreria",
"description": "Busca información en la base de datos de la librería sobre autores y libros.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "La consulta del usuario optimizada: sin saludos, corregida gramaticalmente y enfocada exclusivamente en los criterios de búsqueda (ej: '\''libros de amor de Gabriel García Márquez'\'')."
}
},
"required": ["query"]
}
}
}
],
"think": false,
"stream": false
}'
Respuesta (Qwen 3.5 9B):
{
"model": "qwen3.5:9b-64k",
"created_at": "2026-04-13T05:04:18.274354Z",
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "call_y9mljhip",
"function": {
"index": 0,
"name": "consultar_bd_libreria",
"arguments": {
"query": "libros de amor de Gabriel García Márquez"
}
}
}
]
},
"done": true,
"done_reason": "stop",
"total_duration": 7161121041,
"load_duration": 186818208,
"prompt_eval_count": 382,
"prompt_eval_duration": 4331394542,
"eval_count": 38,
"eval_duration": 2460080082
}
Consulta compleja con el modelo qwen3.5:9b con ventana de 64.000 tokens:
curl -X POST \
'http://localhost:11434/api/chat' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "qwen3.5:9b-64k",
"messages": [
{
"role": "system",
"content": "Eres un asistente virtual de una librería encargado de facilitar información sobre el catálogo de libros y autores disponibles."
},
{
"role": "user",
"content": "¡Buenas! ¿Cómo va todo? Mira, estoy buscando algo de Isabel Allende o tal vez de Gabriel García Márquez, pero que sea de realismo mágico y que no me cueste más de 25 dólares, ¿ya? Ah, y solo si lo tienen ahí en la tienda para pasar a buscarlo hoy mismo, que es para un regalo."
}
],
"tools": [
{
"type": "function",
"function": {
"name": "consultar_bd_libreria",
"description": "Busca información en la base de datos de la librería sobre autores y libros.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "La consulta del usuario optimizada: sin saludos, corregida gramaticalmente y enfocada exclusivamente en los criterios de búsqueda (ej: '\''libros de amor de Gabriel García Márquez'\'')."
}
},
"required": ["query"]
}
}
}
],
"think": false,
"stream": false
}'
Respuesta (Qwen 3.5 9B):
{
"model": "qwen3.5:9b-64k",
"created_at": "2026-04-13T04:59:53.121743Z",
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "call_fqw4hdq7",
"function": {
"index": 0,
"name": "consultar_bd_libreria",
"arguments": {
"query": "libros de realismo mágico de Isabel Allende o Gabriel García Márquez con precio menor a 25 dólares disponibles en tienda"
}
}
}
]
},
"done": true,
"done_reason": "stop",
"total_duration": 15120528125,
"load_duration": 8777821167,
"prompt_eval_count": 431,
"prompt_eval_duration": 2368185708,
"eval_count": 57,
"eval_duration": 3715160875
}
Podemos ver que con un modelo menor como qwen3.5:4b, una instrucción simple no hay problemas:
{
"model": "qwen3.5:4b-64k",
"created_at": "2026-04-13T05:37:48.126052Z",
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "call_emre4xhh",
"function": {
"index": 0,
"name": "consultar_bd_libreria",
"arguments": {
"query": "libros de amor de Gabriel García Márquez"
}
}
}
]
},
"done": true,
"done_reason": "stop",
"total_duration": 8853187542,
"load_duration": 5582010334,
"prompt_eval_count": 382,
"prompt_eval_duration": 1257315083,
"eval_count": 38,
"eval_duration": 1791458750
}
Pero para una consulta compleja, el modelo qwen3.5:4b ya no logra ser eficiente, alucinando fácilmente sin un system prompt más robusto. Ante el mismo texto complejo, el de 4B se mareó, ignoró la herramienta y empezó a chatear:
{
"model": "qwen3.5:4b-64k",
"created_at": "2026-04-13T05:38:48.359164Z",
"message": {
"role": "assistant",
"content": "¡Hola! Todo muy bien por aquí, gracias por preguntar. Me alegra que estés buscando un regalo; el realismo mágico es un género fascinante.\n\nPara poder ayudarte a encontrar exactamente qué tienen en stock hoy en la tienda y que cumpla con tu presupuesto de 25 dólares, necesito que me des una pequeña ayuda con la búsqueda.\n\nPor favor, dime: **¿Prefieres que busque primero por los libros de Isabel Allende o por los de Gabriel García Márquez?** (O si tienes algún título específico en mente, también me lo puedes decir)."
},
"done": true,
"done_reason": "stop",
"total_duration": 11457394291,
"load_duration": 4015661708,
"prompt_eval_count": 431,
"prompt_eval_duration": 1329063875,
"eval_count": 121,
"eval_duration": 5790543085
}
2. Extracción RAG con Razonamiento, Matemáticas y Tono
Le pasé un texto con las reglas de “EcoMóvil”, una empresa ficticia de scooters. Le pedí que calculara el costo de un viaje, resolviera una avería y pregunté por un dato que derechamente no existía en el documento. Todo esto con una regla de sistema estricta: tono amable, cero emojis.
curl -X POST \
'http://localhost:11434/api/chat' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "qwen3.5:9b-64k",
"messages": [
{
"role": "system",
"content": "Eres '\''EcoBot'\'', el asistente virtual de atención al cliente de '\''EcoMóvil'\'', una empresa de alquiler de scooters eléctricos. Tu tono debe ser amable, entusiasta, ecológico y muy profesional. INSTRUCCIÓN ESTRICTA: Tienes absolutamente prohibido utilizar emojis, emoticonos o caracteres gráficos similares en tus respuestas. Mantén un formato de texto limpio. Tu tarea es responder las dudas de los usuarios basándote EXCLUSIVAMENTE en el contexto proporcionado. Si la respuesta no se encuentra en el texto, discúlpate amablemente y explica que no tienes esa información a mano, sin inventar datos.\n\n<contexto_recuperado>\n[ARTICULO_SOPORTE: TARIFAS_Y_USO_2026]\n- Tarifas: Desbloquear un scooter cuesta $1.00 USD. El costo por minuto de uso es de $0.25 USD.\n- Horarios: El servicio opera todos los días desde las 06:00 AM hasta las 11:00 PM. Los scooters se bloquean automáticamente y no pueden iniciarse fuera de este horario.\n- Zonas permitidas: Los scooters solo pueden circular y ser estacionados dentro del '\''Área Metropolitana Centro'\'' y el '\''Campus Universitario'\''. Estacionar fuera de estas zonas conlleva una multa automática de $25.00 USD en la tarjeta asociada.\n- Averías: Si un scooter presenta fallas mecánicas durante el viaje, el usuario debe finalizar el viaje inmediatamente en la app para detener el cobro y presionar el botón '\''Reportar Problema'\'' para notificar al equipo técnico.\n</contexto_recuperado>"
},
{
"role": "user",
"content": "¡Hola! Quería saber cuánto me costaría exactamente un viaje de 20 minutos. También, ¿qué pasa si al scooter se le pincha una rueda a mitad de camino? Ah, y ¿tienen planeado expandir el servicio a la zona norte de la ciudad el próximo mes?"
}
],
"think": false,
"stream": false
}'
Qwen 3.5 9B: Respuesta precisa y natural. Respetó la regla de no usar emojis, admitió no saber la respuesta sobre el dato inventado y el cálculo matemático ($1.00 de desbloqueo + (20 min * $0.25) = $6.00) fue exacto.
{
"model": "qwen3.5:9b-64k",
"created_at": "2026-04-13T06:06:54.100627Z",
"message": {
"role": "assistant",
"content": "¡Hola! Es un gusto saludarte. En EcoMóvil nos encanta que quieras conocer más sobre nuestros servicios.\n\nPara calcular el costo de un viaje de 20 minutos, primero debes considerar que el desbloqueo del scooter cuesta $1.00 USD. Luego, el costo por minuto de uso es de $0.25 USD. Por lo tanto, el viaje de 20 minutos tendría un costo de uso de $5.00 USD (20 minutos multiplicados por $0.25). Sumando el costo de desbloqueo, el total a pagar sería de $6.00 USD.\n\nEn cuanto a la situación de una rueda pinchada, si el scooter presenta fallas mecánicas durante el viaje, es fundamental que finalices el viaje inmediatamente en la aplicación para detener el cobro. Posteriormente, debes presionar el botón 'Reportar Problema' dentro de la app para notificar al equipo técnico y que puedan asistirte.\n\nPor último, respecto a la expansión del servicio a la zona norte de la ciudad, lamentablemente no tengo esa información a mano en este momento. Te recomiendo consultar nuestras redes sociales o la sección de noticias en nuestra aplicación para estar al tanto de los planes de expansión futuros.\n\n¿Hay algo más en lo que pueda ayudarte hoy?"
},
"done": true,
"done_reason": "stop",
"total_duration": 28816119625,
"load_duration": 8543402584,
"prompt_eval_count": 442,
"prompt_eval_duration": 2152467708,
"eval_count": 272,
"eval_duration": 17493256088
}
Qwen 3.5 4B: Mantuvo bien el tono de atención al cliente, pero metió la pata en la lógica matemática en varios de los ejercicios que le tiré después.
{
"model": "qwen3.5:4b-64k",
"created_at": "2026-04-13T05:48:37.869663Z",
"message": {
"role": "assistant",
"content": "¡Hola! Es un placer saludarte. Como asistente de EcoMóvil, estoy aquí para ayudarte a planificar tu viaje de manera eficiente y responsable.\n\nPara calcular el costo de tu viaje de 20 minutos, debemos considerar el costo base por desbloqueo y la tarifa por minuto. El costo inicial para desbloquear un scooter es de 1.00 USD. Además, la tarifa de uso es de 0.25 USD por minuto. Al multiplicar 20 minutos por 0.25 USD, obtenemos un costo de 5.00 USD por el tiempo de uso. Sumando el costo de desbloqueo, el precio total para un viaje de 20 minutos sería de 6.00 USD.\n\nEn cuanto a tu pregunta sobre averías, si un scooter presenta fallas mecánicas durante el viaje, es fundamental que finalices el viaje inmediatamente a través de la aplicación para detener cualquier cobro adicional. Posteriormente, debes presionar el botón 'Reportar Problema' en la app para notificar al equipo técnico, quien se encargará de gestionar la reparación.\n\nRespecto a la expansión del servicio a la zona norte de la ciudad, lamentablemente no tengo esa información disponible en mis registros actuales. Mi base de datos se limita a las tarifas, horarios y zonas permitidas actuales, que son el Área Metropolitana Centro y el Campus Universitario. Estacionar fuera de estas zonas conlleva una multa automática de 25.00 USD, por lo que te recomiendo verificar las rutas oficiales para evitar multas.\n\nQuedo atento si necesitas más información sobre nuestros servicios o tienes alguna otra duda. ¡Espero que tengas un viaje seguro y ecológico!"
},
"done": true,
"done_reason": "stop",
"total_duration": 25273808667,
"load_duration": 5406114208,
"prompt_eval_count": 442,
"prompt_eval_duration": 1319714917,
"eval_count": 359,
"eval_duration": 17672467651
}
Qwen 3.5 2B: Gramaticalmente bien, pero se equivocó en cálculos básicos y ofreció respuestas demasiado escuetas que cortaban la conversación de golpe.
{
"model": "qwen3.5:2b-64k",
"created_at": "2026-04-13T05:58:35.337881Z",
"message": {
"role": "assistant",
"content": "¡Hola! Claro que sí, estoy aquí para ayudarte a planificar tu viaje con EcoMóvil.\n\nUn viaje de 20 minutos costará exactamente $5.00 USD, calculado como $0.25 USD por minuto multiplicado por 20 minutos.\n\nSi al scooter se le pincha una rueda a mitad de camino, te recomendamos finalizar el viaje inmediatamente en la aplicación para detener el cobro y presionar el botón \"Reportar Problema\" para notificar al equipo técnico.\n\nEn cuanto a la expansión de zonas, actualmente el servicio opera dentro del Área Metropolitana Centro y el Campus Universitario. No tengo información disponible sobre planes específicos para expandir el servicio a la zona norte de la ciudad en el próximo mes, pero te recomiendo consultar directamente con nuestro equipo de soporte o revisar nuestra página web para obtener la información más actualizada.\n\nEspero que esta información te sea útil para tu próxima aventura en EcoMóvil. ¡Que tengas un buen día!"
},
"done": true,
"done_reason": "stop",
"total_duration": 11193157167,
"load_duration": 4680604292,
"prompt_eval_count": 442,
"prompt_eval_duration": 535022292,
"eval_count": 205,
"eval_duration": 5662032366
}
Cuando cambiamos el system prompt para una lógica de calculo un poco más compleja, pero simples, solamente el modelo de qwen3.5:9b logra pasar con precisión.
qwen3.5:9b:
{
"model": "qwen3.5:9b-64k",
"created_at": "2026-04-13T06:27:43.570695Z",
"message": {
"role": "assistant",
"content": "Hola. Para calcular el costo total de su viaje de 10 minutos en el Área Centro, aplicaremos los siguientes conceptos:\n\n1. **Costo de desbloqueo:** Dado que la duración del viaje es de 10 minutos (menos de 15 minutos), se aplica una tarifa de desbloqueo de $2.00 USD.\n2. **Tarifa por minuto:** Se cobra $0.25 USD por minuto. Para 10 minutos, el costo es de $2.50 USD.\n3. **Multa por zona:** El viaje se realiza dentro del Área Centro, por lo que no se aplica ninguna multa.\n\n**Cálculo final:**\n$2.00 (desbloqueo) + $2.50 (tarifa por minuto) = $4.50 USD.\n\nEl costo total de su viaje será de **$4.50 USD**."
},
"done": true,
"done_reason": "stop",
"total_duration": 22793113666,
"load_duration": 8255305416,
"prompt_eval_count": 186,
"prompt_eval_duration": 1053119459,
"eval_count": 197,
"eval_duration": 12840003246
}
qwen3.5:4b:
{
"model": "qwen3.5:4b-64k",
"created_at": "2026-04-13T06:26:00.84569Z",
"message": {
"role": "assistant",
"content": "Hola. Para calcular el costo total de su viaje de 10 minutos dentro de la Zona Centro, primero debemos determinar el costo del desbloqueo.\n\nDado que su viaje dura 10 minutos, que es menos de 15 minutos, el desbloqueo no es gratuito y se calcula según la tarifa de $0.25 USD por minuto. El costo del desbloqueo es de $2.50 USD (10 minutos x $0.25).\n\nAsumiendo que no hay otros cargos adicionales como multas por salir de la zona, el costo total del viaje es de $2.50 USD."
},
"done": true,
"done_reason": "stop",
"total_duration": 9396311125,
"load_duration": 480919291,
"prompt_eval_count": 186,
"prompt_eval_duration": 779439167,
"eval_count": 135,
"eval_duration": 6620469968
}
qwen3.5:2b:
{
"model": "qwen3.5:2b-64k",
"created_at": "2026-04-13T06:22:52.715915Z",
"message": {
"role": "assistant",
"content": "Hola. Para realizar un viaje de 10 minutos dentro del Centro, la tarifa de desbloqueo es de $2.00 USD."
},
"done": true,
"done_reason": "stop",
"total_duration": 5984044125,
"load_duration": 4802225125,
"prompt_eval_count": 186,
"prompt_eval_duration": 290848333,
"eval_count": 31,
"eval_duration": 796598664
}
3. Como asistente de desarrollo
Lo conecté a OpenCode, Copilot y Claude Code. La versión de 9B funciona bien para autocompletar y refactorizar en local. Si vas a armar arquitecturas complejas, vas a necesitar los modelos más grandes, y ahí sí o sí necesitas un servidor Cloud o un equipo local bastante robusto (como una Mac Mini con 32GB o 64GB de RAM).
Benchmarks qwen3.5
En el benchmark oficial podemos ver todo su poder comparado a otros modelos:
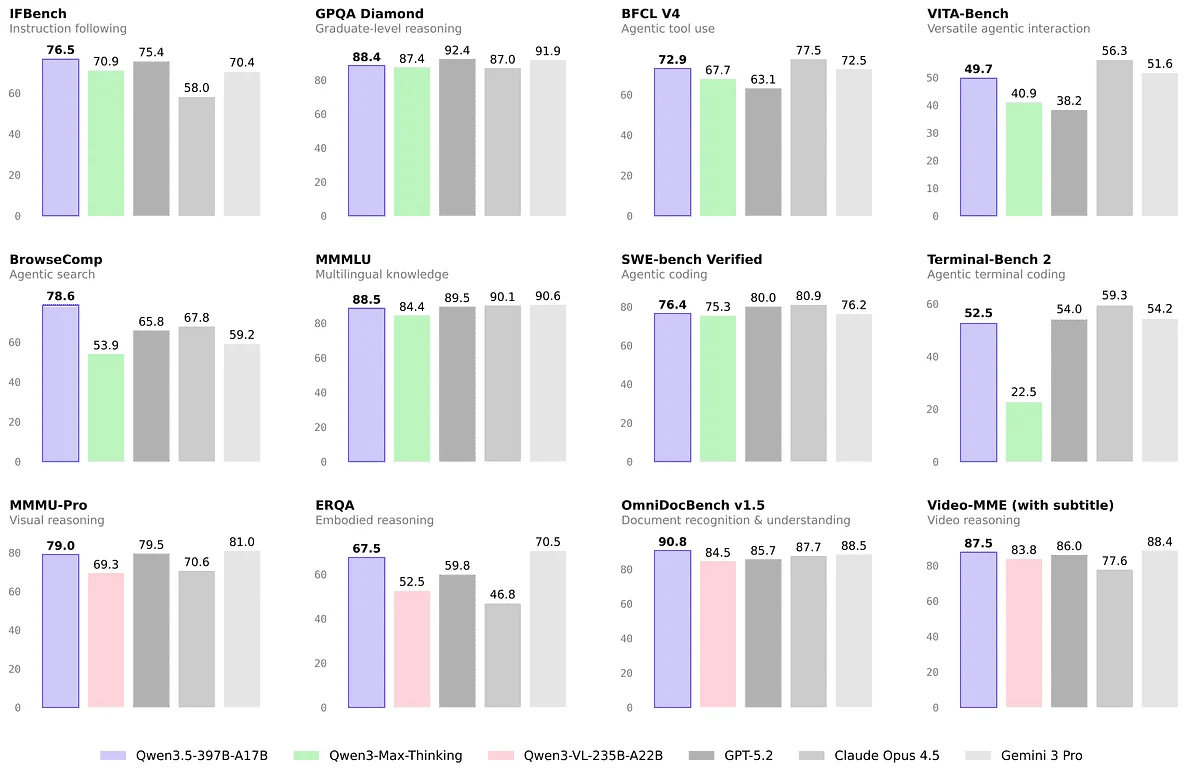
Si miramos los números oficiales contra modelos comerciales, la diferencia de rendimiento vs precio es abismal:
El verdadero salto de Qwen 3.5 está en su uso como agente autónomo. En el benchmark BrowseComp (búsqueda y navegación web automatizada), llega a 78.6 puntos. Supera por bastante a Gemini 3 Pro (59.2) y pisa los talones de Claude 4.5 Opus (84.0).
Al orquestar APIs o procesar datos externos, Qwen 3.5 le compite cara a cara a modelos de pago mucho más caros. Es la prueba de que hoy una empresa puede dejar de depender exclusivamente de proveedores externos para su core de IA.
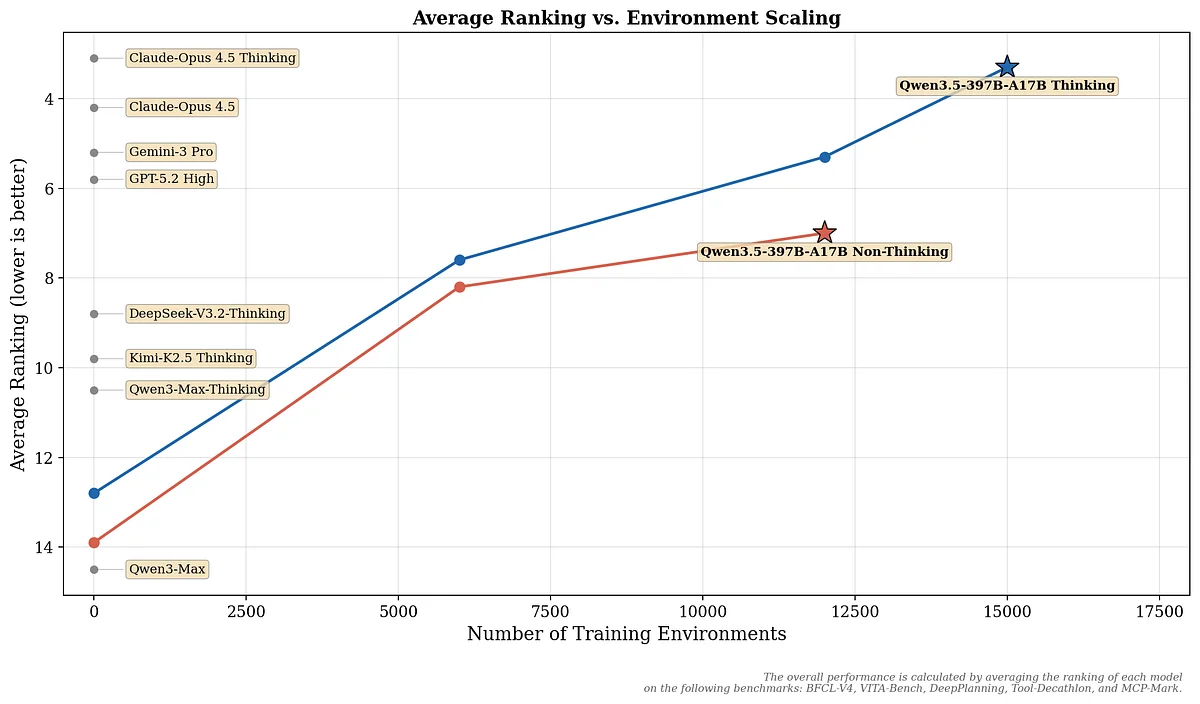
¿Cuándo vale la pena ir por modelos Open-Weights?
- Uso masivo de tokens: Si tu producto quema millones de tokens al mes, la factura de las APIs va a doler. Hay que hacer bien la matemática (servidores vs API), pero alojar un modelo como
qwen3.5puede bajar la cuenta mensual en más del 90%. - Reglas estrictas de privacidad: Si trabajas con datos médicos, PII o financieros, tu VPC es tu refugio. Ejecutar todo en local te garantiza que los datos nunca tocan un servidor de terceros.
- Personalización a medida: Cuando necesitas hacer fine-tuning para que el modelo hable el lenguaje técnico de tu industria sin tener que entrenar un modelo fundacional desde cero.
Conclusión
La realidad es que para el 80% de las operaciones con LLMs en producción (clasificar textos, RAG, tool calling), no hace falta pagar por el modelo más inteligente del mercado.
Puedes delegar gran parte de la carga de trabajo a modelos open-weights alojados por ti, sobre todo en tareas en segundo plano. La arquitectura ideal hoy es tener un buen enrutador: usas modelos locales rápidos y baratos para las tareas simples, y solo llamas a los modelos gigantes comerciales cuando el razonamiento complejo lo exige.
Mi recomendación es que antes de hacer este cambio te asegures de tener buena observabilidad, conjuntos de datos de pruebas sólidos y una gestión de prompts adecuada (con herramientas como Langfuse). Aquí es donde los modelos open-weights también brillan, permitiendo invocar miles de LLM-as-a-Judge sin impacto en los costos, aumentando las trazas evaluadas y mejorando las métricas en las evaluaciones online.
Y tú, ¿ya estás moviendo tus cargas de trabajo a modelos locales o sigues dependiendo al 100% de APIs de terceros?