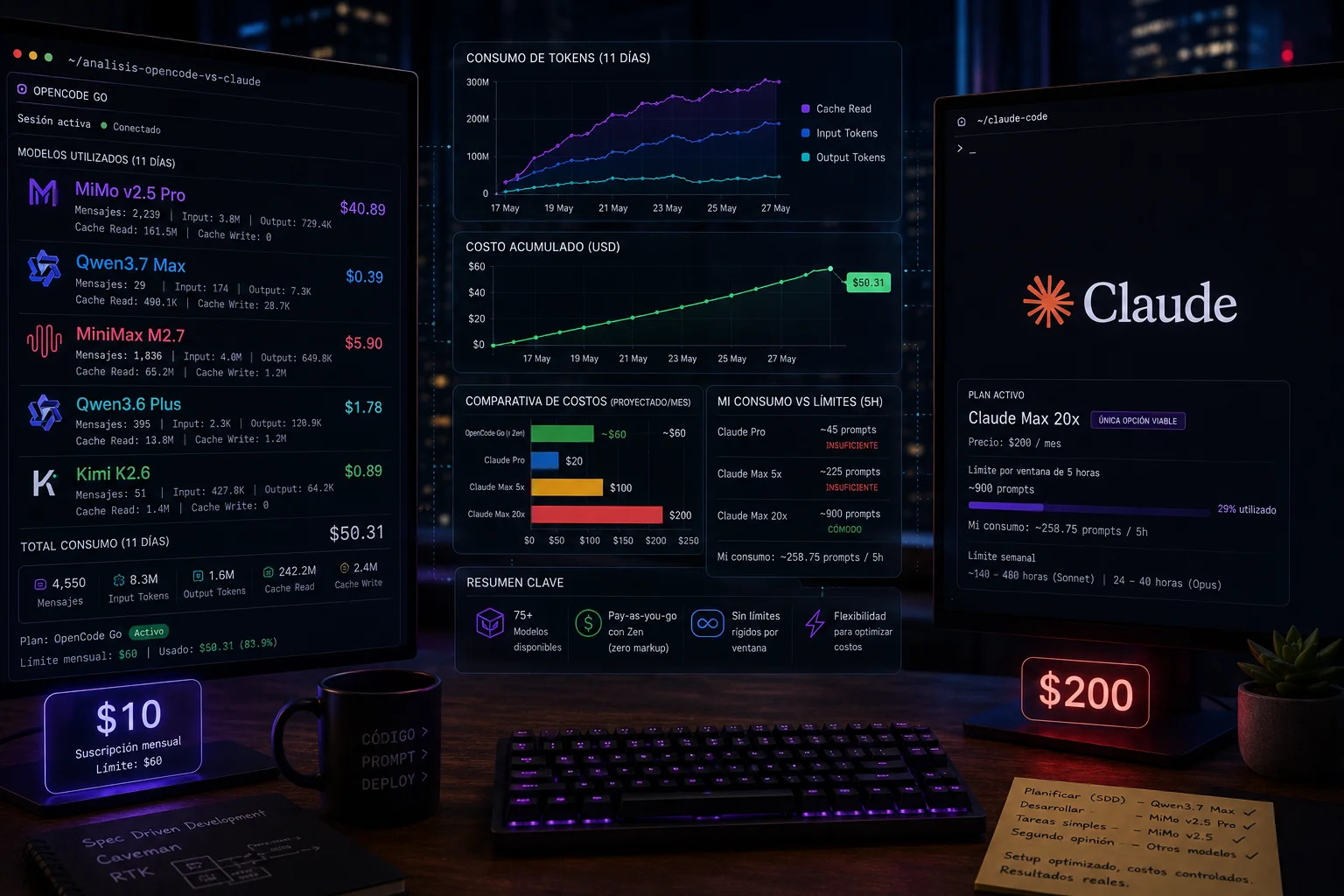
>_ Opencode Go vs Claude Code: Uma análise real de 11 dias
$60 em consumo de API por $10 de assinatura. Uma análise real de 11 dias comparando Opencode Go vs Claude Code: custos, limites e quando vale a pena trocar.
// recent_posts — últimos publicados
ls -la arquivo →
Desmistificando o AI First: a prioridade estratégica
AI First não é colocar IA em tudo nem uma estratégia isolada. É uma prioridade estratégica que convive com Data First, Security First e Cloud First. O papel do arquiteto: garantir que as prioridades fora do top 5 não se percam.

Multi-Agente: além da velocidade, uma estratégia para isolar contexto e otimizar custos
Quando alguém começa a operar com agentes, o primeiro instinto costuma ser carregar o main agent com todas as skills disponíveis, todas as ferramentas conectadas e um system prompt gigante onde se...

HITL em Vibe Coding e IaC: Evite a Conta Longa
Em 2026, o discurso corporativo vai quase tudo em uma única direção: agentes autônomos, full automation, self-healing pipelines. A promessa é sedutora porque vende. A realidade operacional é que quase...

Fine-tuning vs. RAG: Quando Cada Um Tem ROI Real em Produção
Já vimos como reduzir o custo de inferência usando modelos open-weight como o Qwen 3.5 no artigo Reduzindo o custo em produção: Qwen 3.5 na AWS vs APIs Comerciais. Mas quando você tem o custo base sob controle, enfrenta outro problema: como dar ao modelo conhecimento específico da sua empresa.

LLM-as-a-Judge: como construir pipelines de avaliação de IA que escalonam
Os prompts em sistemas com Large Language Models (LLMs) não se comportam como código determinístico. Em um desenvolvimento de software tradicional, se você modifica uma função e todos os testes passam, você pode...

Auditoria de Skills: Protegendo sua Infraestrutura dos Sleeping Payloads
Skills e agentes são provavelmente o melhor que aconteceu com o ecossistema de IA nos últimos anos. Uma skill é, em essência, uma abstração poderosa: encapsula conhecimento e scripts...

Reduzindo o Custo em Produção: Qwen 3.5 na AWS vs OpenAI
Análise técnica: AWS SageMaker vs OpenAI. Descubra por que hospedar modelos open-weights é vital para rentabilidade e latência.

Antonio Barbosa
Engenheiro de Software com mais de 19 anos de experiência liderando o design, desenvolvimento e escalabilidade de sistemas em empresas como Buk, Walmart Chile, Cencosud e Globant. Meu trabalho cobre o ciclo completo: arquitetura backend, cloud, DevOps, frontend e, recentemente, integração de Large Language Models (LLMs) e funcionalidades agentic AI em produção.