>_ Opencode Go vs Claude Code: A real 11-day analysis
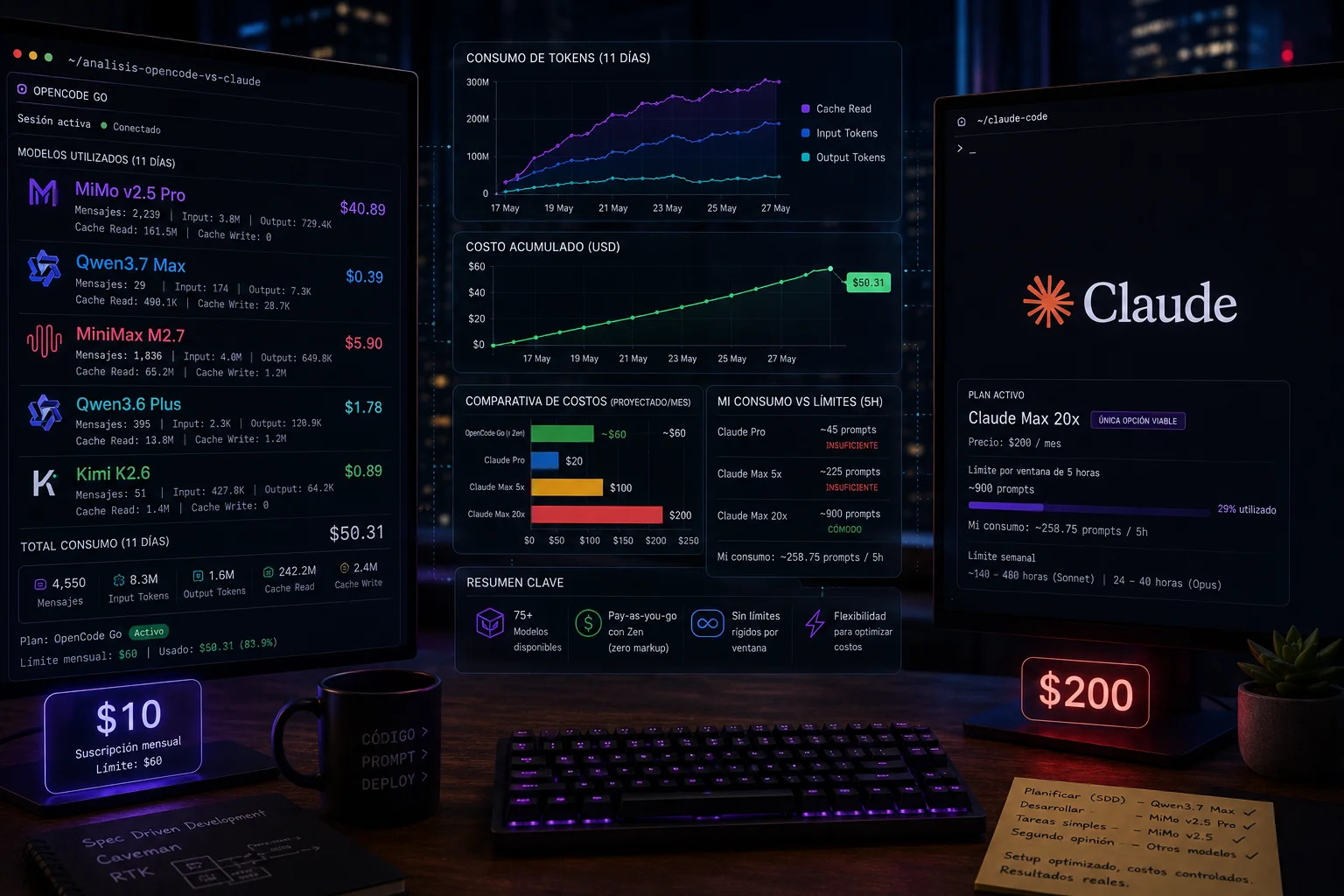
$60 in API consumption for a $10 subscription. A real 11-day analysis comparing Opencode Go vs Claude Code: costs, limits, and when it makes sense to switch.
// recent_posts — latest published
ls -la archive →
Demystifying AI First: The Strategic Priority
AI First isn't about putting AI in everything nor an isolated strategy. It's a strategic priority that coexists with Data First, Security First, and Cloud First. The architect's role: ensuring priorities outside the top 5 don't get lost.

Multi-Agent: beyond speed, a strategy to isolate context and optimize costs
When someone starts working with agents, the first instinct is usually to load the main agent with all available skills, all connected tools, and a giant system prompt where you...

HITL in Vibe Coding and IaC: Avoid the Long Bill
In 2026, corporate discourse goes almost entirely in one direction: autonomous agents, full automation, self-healing pipelines. The promise is seductive because it sells. The operational reality is that almost...

Fine-tuning vs. RAG: When Each One Has Real ROI in Production
We already saw how to lower inference costs using open-weight models like Qwen 3.5 in the article Reducing Production Costs: Qwen 3.5 on AWS vs Commercial APIs. But once you have the base cost under control, you face another problem: how to give the model specific knowledge about your business.

LLM-as-a-Judge: how to build scalable AI evaluation pipelines
Prompts in systems with Large Language Models (LLMs) don't behave like deterministic code. In traditional software development, if you modify a function and all tests pass, you can...

Skills Audit: Protecting Your Infrastructure from Sleeping Payloads
Skills and agents are arguably the best thing that has happened to the AI ecosystem in recent years. A skill is, in essence, a powerful abstraction: it encapsulates knowledge and scripts...

Reducing Production Costs: Qwen 3.5 on AWS vs OpenAI
Technical analysis: AWS SageMaker vs OpenAI. Discover why hosting open-weight models is critical for profitability and latency.

Antonio Barbosa
Software Engineer with 19+ years of experience leading the design, development, and scaling of systems at companies like Buk, Walmart Chile, Cencosud, and Globant. My work covers the full cycle: backend architecture, cloud, DevOps, frontend, and recently integrating Large Language Models (LLMs) and agentic AI capabilities in production.